Вы можете победить бинарный поиск

Иногда нам нужно найти значение в отсортированном массиве. Простейший алгоритм заключается в последовательном переборе значений, пока мы не встретим искомое значение или не достигнем конца массива. Такой алгоритм иногда называют линейным поиском. В C++ добиться такого же эффекта можно с помощью функции std::find.
Для больших массивов лучшего результата можно достичь с помощью бинарного поиска. Бинарный поиск является классическим алгоритмом, который эффективно находит целевое значение в отсортированном массиве, многократно деля интервал поиска пополам. Начиная со всего массива, он сравнивает целевое значение со средним элементом: если цель меньше, верхняя половина отбрасывается; если больше — отбрасывается нижняя. Этот процесс продолжается, пока цель не будет найдена или интервал не станет пустым. На больших наборах данных бинарный поиск значительно быстрее линейного. В C++ он реализован функцией std::binary_search, которая возвращает true или false в зависимости от существования элемента.
Популярный формат Roaring Bitmap использует массивы 16-битных целых чисел размером от 1 до 4096 элементов. Иногда нам приходится проверить, существует ли значение в этом массиве. Для этого мы используем бинарный поиск.
Я захотел создать более быстрый подход. У меня были две мысли:
Практически все процессоры сегодня имеют инструкции для параллельной обработки данных (также называемая SIMD), которые могут проверять несколько значений за раз. И 64-битные ARM, и x64 процессоры (Intel/AMD) всегда поддерживают сравнение восьми 16-битных чисел с искомым значением используя всего одну инструкцию. Это подсказывает, что не стоит углубляться в бинарном поиске до блоков размером меньше восьми элементов. Кроме того, имеет смысл сравнивать шестнадцать элементов и больше.
Бинарный поиск проверяет одно значение за раз. Однако, современные процессоры могут загружать и проверять более одного значения одновременно. Они обладают прекрасным параллелизмом на уровне памяти. Это говорит о том, что вместо бинарного поиска, стоит попробовать четверичный поиск: вместо того чтобы делить массив пополам, мы можем разделить их на четыре части. Конечный результат может потребовать чуть больше инструкций, но количество инструкций перестанет являться ограничивающим фактором.
Так я и создал алгоритм, который называю SIMD Quad. Это эффективный алгоритм поиска в отсортированных массивах с 16 битными беззнаковыми целыми числами, сочетающий четверичный интерполяционный поиск с SIMD (Single Instruction, Multiple Data). Алгоритм делит массив на блоки фиксированного размера по 16 элементов (возможно, за исключением последнего блока) и использует последний элемент каждого блока как интерполяционный ключ, чтобы быстро сузить область поиска до одного блока, а затем применяет SIMD-инструкции для одновременной проверки всех 16 элементов в этом блоке.
В основе лежит идея выполнения иерархического поиска: сначала используется интерполяционный поиск на более грубом уровне (по границам блоков), чтобы найти блок, содержащий целевое значение, а затем происходит переключение на SIMD для точной параллельной проверки внутри блока. Этот гибридный подход использует и сильные стороны алгоритмической оптимизации, так и аппаратного ускорения (SIMD проверяет несколько элементов за раз).
Начальная проверка: если в массиве менее 16 элементов, выполняется простой линейный поиск
Разбиение на блоки: массив делится на блоки по 16 последовательных элементов. Для массива размером cardinality существует num_blocks = cardinality / 16 полных блоков.
Четверичный интерполяционный поиск: используем последний элемент каждого блока (на позициях 16-1, 32-1 и других) как ключи для интерполяции. Поиск выполняет четверичную (по основанию 4) интерполяцию, чтобы найти блок, в котором, вероятно, находится целевое значение. Это включает в себя сравнение цели с точками, делящими текущий диапазон поиска на четверти.
Выбор блока: после сужения диапазона выбирается подходящий индекс блока lo на основе результатов интерполяции.
SIMD-проверка: если найден верный блок, 16 элементов загружаются в SIMD-регистры (с использованием NEON на ARM или SSE2 на x64), после чего выполняются параллельные сравнения на равенство с целевым значением. Если найдено найдено хотя бы одно совпадание, возвращается true.
Проверка остатка: для элементов, не вошедших в полные блоки (остаток) выполняется линейный поиск.
Каковы результаты этого? Я написал бенчмарк. Бенчмарк работает следующим образом: для каждого массива размером от 2 до 4096 элементов генерируется 100,000 сортированных массивов с 16-битными беззнаковыми целыми числами. Для каждого размера выполняется 10 миллионов запросов на принадлежность в «холодном» режиме (каждый запрос ищет в другом массиве, имитируя промахи кэша) и 10 миллионов запросов в «горячем» режиме (запросы сгруппированы по массивам, каждый массив обыскивается 100 раз подряд, имитируя попадания в кэш). Бенчмарк измеряет среднее время на один запрос для трёх алгоритмов: линейного поиска (std::find), бинарного поиска (std::binary_search) и нового алгоритма SIMD Quad.
Я использую две системы: Apple M4 с Apple LLVM и процессор Intel Emerald Rapids с GCC.
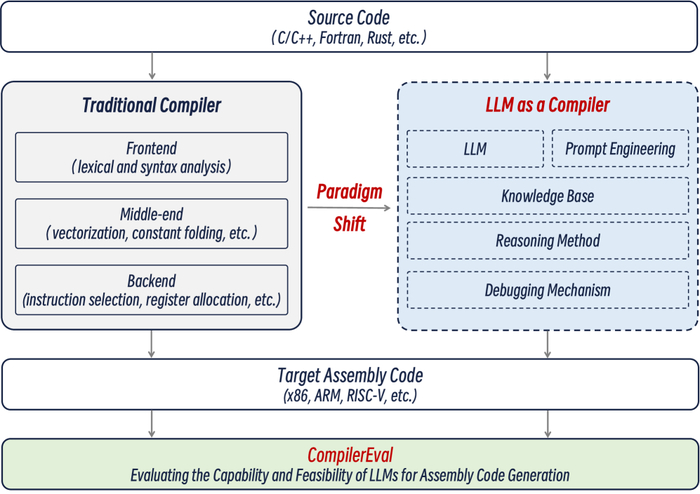
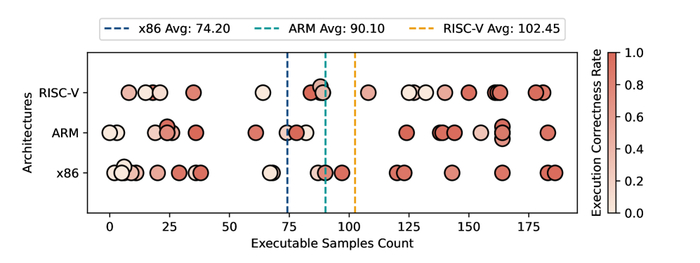
Во-первых, давайте сравним линейный и бинарный поиск.
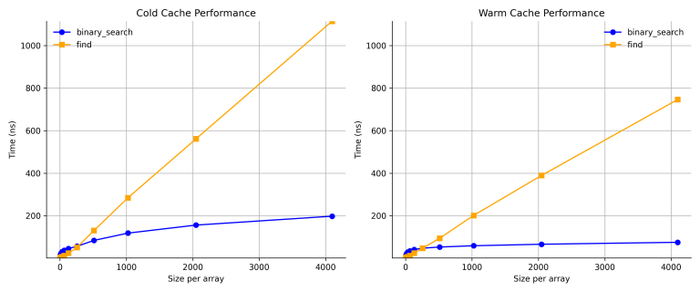
Intel/GCC
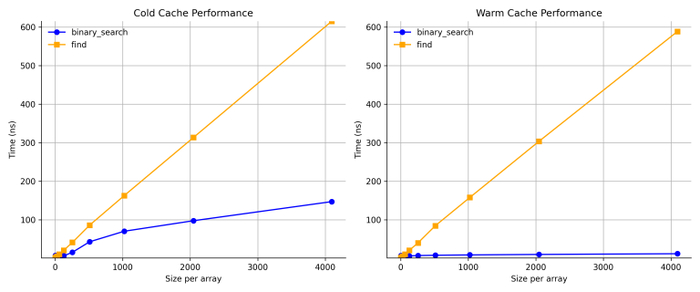
Apple/LLVM
Результат ясен. Бинарный поиск лучше чем линейный поиск, как только массивы становятся большими. Этого следовало ожидать.
На холодном кэше линейный поиск относительно хуже. Этого следует ожидать, потому что он получает доступ к большему количеству данных, вызывая больше ошибок кэша.
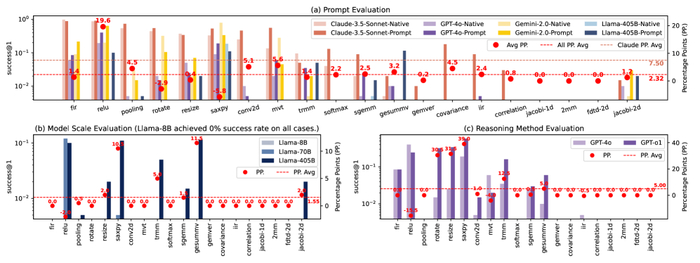
Мы установили, что бинарный поиск является чистым победителем по линейному поиску. Давайте теперь сравним с алгоритмом SIMD Quad.
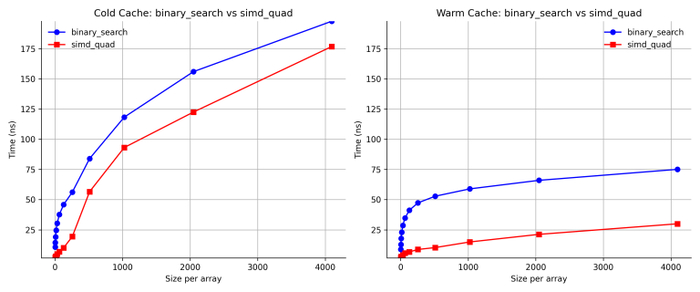
Intel/GCC
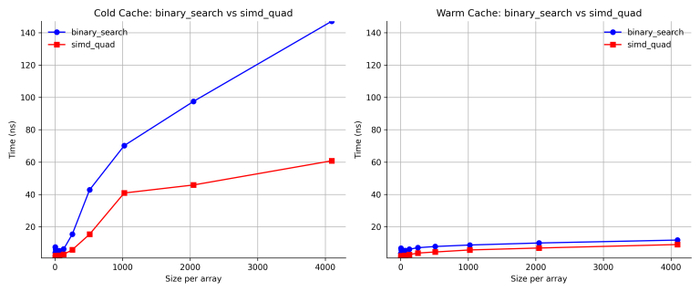
Apple/LLVM
Результаты заметно различаются между Intel и Apple. На Intel SIMD Quad более чем вдвое быстрее бинарного поиска на «горячем» кэше. На «холодном» кэше преимущества меньше. На платформе Apple ситуация обратная: именно на «холодном» кэше SIMD Quad оказывается более чем вдвое быстрее, тогда как на «горячем» кэше выигрыш более скромный.
Но важней вывод заключается в том, что во всех случаях SIMD Quad быстрее бинарного поиска.
SIMD-компонент алгоритма довольно прост: мы используем специализированные инструкции, которые сокращают объем работы. ПОэтому легко понять, почму это может ускорить процесс - меньше инструкций, меньше ветвлений.
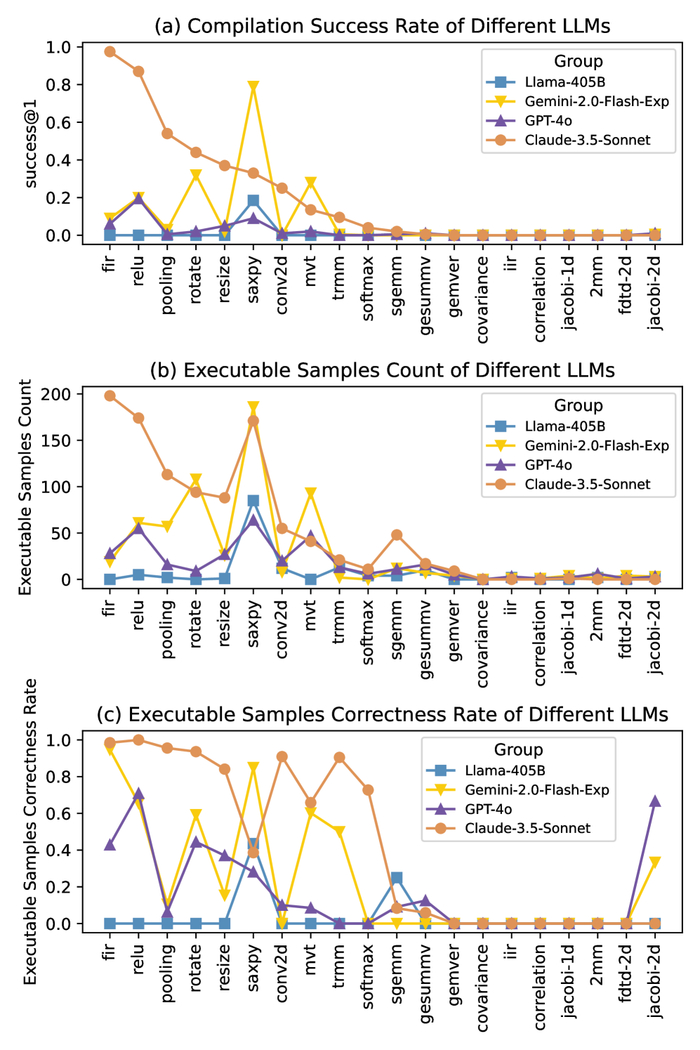
Но как насчет «четверичной» (quad) части? Тогда я опробовал бинарную версию того же алгоритма. В нем присутствует та же SIMD-оптимизация, но я отказался от четверичного интерполяционного поиска и заменяю его стандартным бинарным поиском.
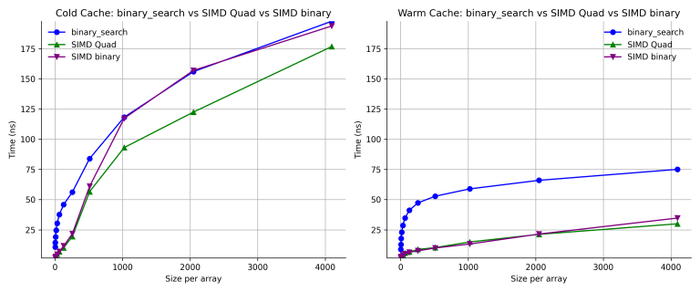
Intel/GCC
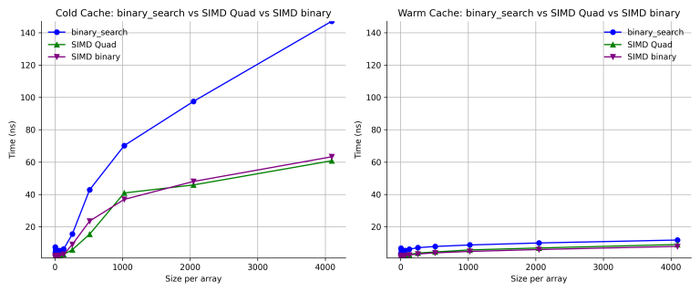
Apple/LLVM
Говоря простыми словами, подход с четверичным поиском (quad) почти и не дает эффекта на Apple, однако на Intel он является неплохой оптимизацией для больших массивов в «холодном» режиме. Четверичный поиск лучше задействует параллелизм на уровне памяти на моём Intel-сервере.
Заключение: мои результаты говорят о том, что, хотя классический бинарный алгоритм из учебника — вполне достойный, его можно улучшить, причем ощутимо. Стандартные алгоритмы зачастую не проектировались под компьютеры с таким объемом параллелизма. Алгоритм SIMD Quad пытается задействовать и параллелизм на уровне памяти, и параллелизм на уровне данных. Более того, я подозреваю, что можно добиться даже большего, чем даёт мой алгоритм. Будьте креативнее!
❯ Исходный код
bool simd_quad(const uint16_t *carr, int32_t cardinality,
uint16_t pos) {
constexpr int32_t gap = 16;
if (cardinality < gap) {
for (int32_t j = 0; j < cardinality; j++) {
if (carr[j] == pos) return true;
}
return false;
}
int32_t num_blocks = cardinality / gap;
int32_t base = 0;
int32_t n = num_blocks;
while (n > 3) {
int32_t quarter = n >> 2;
int32_t k1 = carr[(base + quarter + 1) * gap - 1];
int32_t k2 = carr[(base + 2 * quarter + 1) * gap - 1];
int32_t k3 = carr[(base + 3 * quarter + 1) * gap - 1];
int32_t c1 = (k1 < pos);
int32_t c2 = (k2 < pos);
int32_t c3 = (k3 < pos);
base += (c1 + c2 + c3) * quarter;
n -= 3 * quarter;
}
while (n > 1) {
int32_t half = n >> 1;
base = (carr[(base + half + 1) * gap - 1] < pos)
? base + half : base;
n -= half;
}
int32_t lo = (carr[(base + 1) * gap - 1] < pos)
? base + 1 : base;
if (lo < num_blocks) {
const uint16_t *blk = carr + lo * gap;
#ifdef __ARM_NEON
uint16x8_t needle = vdupq_n_u16(pos);
uint16x8_t v0 = vld1q_u16(blk);
uint16x8_t v1 = vld1q_u16(blk + 8);
uint16x8_t hit = vorrq_u16(vceqq_u16(v0, needle),
vceqq_u16(v1, needle));
return vmaxvq_u16(hit) != 0;
#else
__m128i needle = _mm_set1_epi16((short)pos);
__m128i v0 = _mm_loadu_si128((const __m128i *)blk);
__m128i v1 = _mm_loadu_si128((const __m128i *)(blk + 8));
__m128i hit = _mm_or_si128(_mm_cmpeq_epi16(v0, needle),
_mm_cmpeq_epi16(v1, needle));
return _mm_movemask_epi8(hit) != 0;
#endif
}
for (int32_t j = num_blocks * gap; j < cardinality; j++) {
uint16_t v = carr[j];
if (v >= pos) return (v == pos);
}
return false;
}
Автор оригинальной статьи: Daniel Lemire
Автор перевода: DrArgentum
Написано при поддержке Timeweb Cloud ↩
Больше интересных статей и новостей в нашем блоге на Хабре и телеграм-канале.

📚 Вам может быть интересно:
Реклама. ООО «ТАЙМВЭБ.КЛАУД», ИНН: 7810945525