
Закреплено

Искусственный интеллект
5 819 постов
•
11 949 подписчиков
0 просмотренных постов скрыто


Open Dungeon — полностью локальный AI-ролеплей: и сюжет, и картинки генерятся на твоём ПК
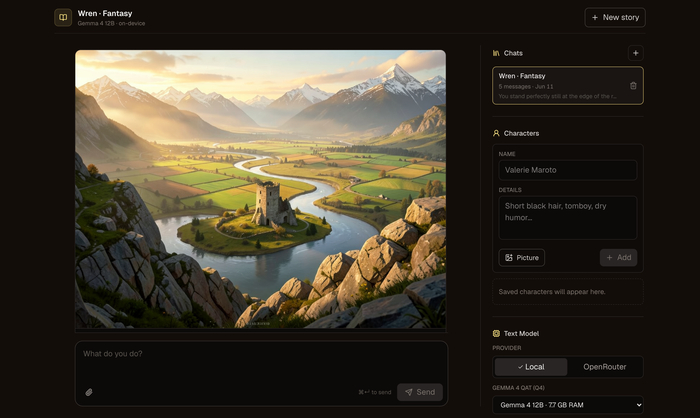
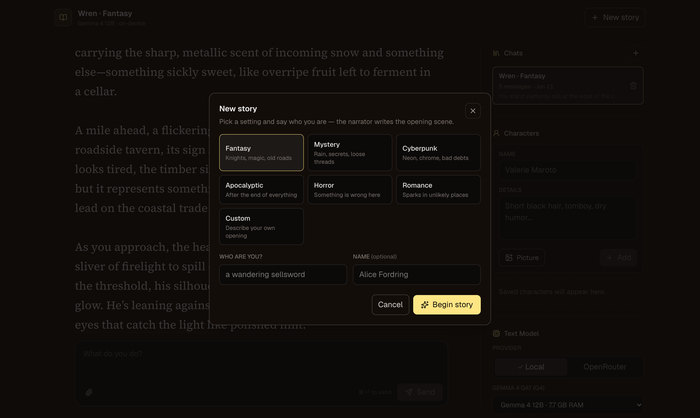
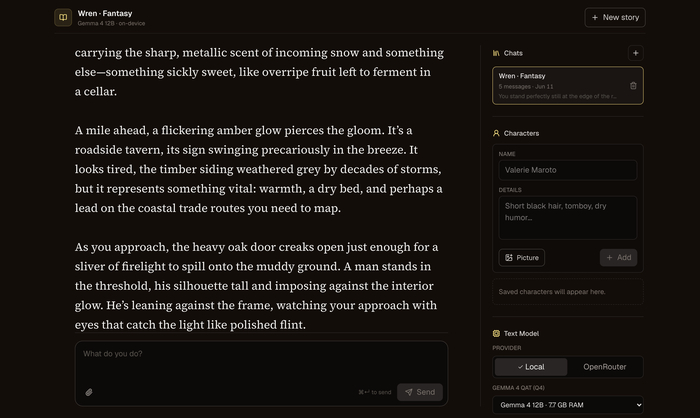
Open Dungeon — первый по-настоящему полностью локальный AI-ролеплей. ИИ-рассказчик ведёт историю в реальном времени, а сцены тут же иллюстрируются картинками — и всё это считается на твоей машине. Ни аккаунтов, ни API-ключей, ни облака: истории, персонажи и картинки лежат в локальной SQLite и никуда не утекают.
Текст генерит Gemma 4 (QAT) через Ollama — хватит и 4 ГБ ОЗУ под младшую модель, а 12B-вариант кушает около 8 ГБ. Картинки сцен рисует FLUX.2 (опционально, на CUDA / CPU / Apple Silicon). Старт в один клик: выбираешь сеттинг (фэнтези, киберпанк, хоррор, апокалипсис…), говоришь, кто ты, — и рассказчик пишет завязку.
Из приятного: режимы ввода Do / Say / Story, правка любого абзаца, память на 128–256K токенов со сворачиванием старого в «summary истории», персонажи с визуальной преемственностью и возможность играть с телефона по Tailscale. Лицензия MIT, есть лаунчеры под Windows (.bat), DMG под macOS и установка под Linux.
Любопытно ещё и лично: я сам когда-то ваял подобное — генеративное приключение, где каждый ход рождал новый бой, локацию или квест, и под это рисовались картинки. Только у меня всё умещалось в одном HTML-файле, а здесь — доведённый до ума готовый продукт. Тем интереснее разобрать, как автор это собрал.
🔗 GitHub: newideas99/open-dungeon
Показать полностью
3
Две статьи в Nature за один день: ИИ диагностирует точнее живых докторов

Последние месяцы разговоры про ИИ крутятся вокруг денег: пузырь или не пузырь, чьи капитализации раздуты, кто кого купит. А в Nature тем временем тихо вышли две рецензируемые работы, которые бьют в куда более чувствительную точку, чем любой инвестраунд. Они показывают: в контролируемых условиях медицинский ИИ ставит диагноз и назначает лечение точнее, чем живые врачи. И это не маркетинговое демо со сцены, а слепые сравнения на сотнях клинических случаев — то, на чём в медицине вообще-то и строится доказательность.
MIRA: 87,8% против 78,1%
Первая система, немецкая MIRA, — это не чат-бот, которому скармливают симптомы. Это автономный агент, живущий внутри виртуальной электронной карты пациента: он сам собирает анамнез, назначает обследования, читает результаты, ставит диагноз и пишет план лечения. Под капотом — модели OpenAI GPT-4o и o1. На массиве из более чем 500 экстренных случаев точность диагноза составила 88,9%. А в честном очном сравнении на 311 идентичных кейсах MIRA дала 87,8% верных диагнозов против 78,1% у опытных врачей-специалистов.
Дьявол, как всегда, в деталях. Аппендицит система узнаёт почти безошибочно — 98,6%, панкреатит — в 92,3% случаев. А вот там, где картина смазана, ИИ пока проседает: пневмония — 72,4%, инфекции мочевыводящих путей — 77,6%. Но есть цифра, которая важнее средней точности: при проверке безопасности эксперты не нашли ни одного опасного лекарственного взаимодействия и ни одной ошибки в дозировке. Именно этого все боялись от «врача-галлюцинатора» — и именно этого не случилось.
AMIE: план лечения лучше, чем у 21 терапевта
Вторая система — AMIE от Google — устроена принципиально иначе. Это связка из двух агентов: один ведёт диалог с пациентом, второй параллельно занимается клиническими рассуждениями. Её гоняли не на разовом диагнозе, а на ведении пациента через несколько визитов — то есть на куда более близкой к реальности задаче. Результат: уже на первом приёме AMIE предлагала адекватный план лечения в 95% случаев против 72% у живых врачей. По точности назначений и следованию клиническим рекомендациям она обошла 21 врача первичного звена.
Любопытный отрезвляющий штрих: отдельный тест на знание лекарств одинаково плохо прошли обе стороны — и люди, и ИИ набрали меньше 75%. То есть машина не «всезнающа», она просто системнее держит протокол.
Парадокс: работа рискует устареть раньше, чем её прочитают
А вот здесь спрятан самый неудобный вывод обеих статей. И MIRA, и AMIE — это не «голая модель», а сложная инженерная обвязка вокруг неё: структурированные рассуждения, принудительная сверка с гайдлайнами, многоагентная архитектура. Именно эти костыли и вытягивали результат на моделях прошлого поколения. Но когда исследователи подставили внутрь свежую Gemini 2.5 Flash, эффект от надстроек почти растворился — базовая модель и так оказалась достаточно сильной, чтобы обойтись без них.
Перевожу с научного: значительная часть того, что авторы кропотливо собирали как ноу-хау, может стать ненужной быстрее, чем статьи дойдут до читателя. Это судьба всей прикладной ИИ-инженерии прямо сейчас — ты строишь леса вокруг модели, а через полгода выходит модель, которой леса не нужны.
Что это на самом деле значит
Вывод двойной, и оба конца важны. С одной стороны, это первое серьёзное, рецензируемое подтверждение, что ИИ в медицине перерос роль «подсказчика»: в контролируемом поле он обыгрывает врачей и по диагнозу, и по плану лечения, не убивая при этом пациента дозировкой. С другой — пока это симулированные пациенты и виртуальные карты, а не живой приём с его шумом, болью, недосказанностью и юридической ответственностью за исход.
Но вектор задан предельно чётко. Вопрос с повестки «а может ли ИИ ставить диагнозы» уже снят. Новый вопрос звучит жёстче: как быстро базовые модели станут настолько хороши, что сделают лишними не только костыли вокруг них, но и часть людей в белых халатах.
Показать полностью

Как поговорить с ИИ-персонажем или собрать своего

Обычно к нейросети идут с задачей: разобраться в каком-то вопросе, составить план, написать черновик письма. Но бывает, что хочется не задачу решить, а просто поговорить — выговориться, получить совет или развлечься. Для таких случаев в чате с Алисой AI появились ИИ-персонажи: у каждого свой характер и своя манера общения.
Сейчас их больше тридцати — от популярного блогера до аниме-героини, можно выбрать собеседника под любое настроение. Один выслушает и поддержит, другой подскажет, с чего начать работу над собой.
Если ни один из готовых персонажей не подходит, можно собрать своего. Для этого нужно придумать ему имя и подробно описать, как он должен себя вести. Например, остроумного киномана, который любит шутить и цитировать героев сериалов, — и дальше общаться уже с ним.
Разговор с персонажем не обнуляется после каждого сообщения. Можно часами обсуждать одну тему, закрыть чат и вернуться позже — персонаж запомнит, на чём вы остановились. А если захочется сменить тему, достаточно начать диалог заново.
Персонажи не заменяют Алису AI, а дополняют её. К самой нейросети по-прежнему идут с повседневными задачами, а к персонажу — чтобы пообщаться, развлечься или чему-то научиться. Это разные сценарии, и теперь они живут в одном чате.
Пока это начало: дальше с персонажами можно будет обсуждать актуальные события, а ещё у них появятся голоса. Попробовать общение можно уже сейчас — на alice.yandex.ru, в приложениях Алиса AI и Яндекс, а также в Яндекс Браузере.
Показать полностью
«Крёстный отец ИИ» Ян ЛеКун назвал xAI Маска провалом и предупредил о «взрыве пузыря» — при чём тут доткомы

Один из «крёстных отцов ИИ», лауреат премии Тьюринга Ян ЛеКун, в интервью CNBC выдал сразу два громких тезиса: компания Илона Маска xAI — «откровенно говоря, своего рода провал», а всю ИИ-индустрию может ждать «большой взрыв пузыря». Учитывая, кто это говорит, отмахнуться не получится — но и принимать на веру целиком тоже не стоит. Разберёмся по порядку.
«xAI — это провал». ЛеКун не стал подбирать слова: по его словам, из xAI ушли «фактически все фаундеры, кроме Илона Маска». Последним из первоначальной команды из 11 человек считается Росс Нордин, которого, как сообщается, выдавили из компании, отрезав доступ к системам. Маск, считает ЛеКун, загнал себя в угол: «ему теперь очень, очень тяжело нанимать топовых людей в ИИ, потому что он повёл себя не лучшим образом с прежней командой». Главный актив xAI — гигантская вычислительная инфраструктура, «которую он сдаёт в аренду другим, потому что только так может отбить затраты». Вывод ЛеКуна: с «OpenAI и Anthropic этого мира» xAI конкурировать не сможет.
Тезис о пузыре. Дальше ЛеКун переходит от частного к общему. Экономика всей отрасли, по его мнению, нездорова: цены на ИИ-сервисы растут, но затраты на их работу падают медленнее, чем хотелось бы. Итог — «все эти компании теряют деньги, а инвесторы по сути субсидируют использование». Пока венчурные миллиарды льются рекой, это незаметно; но если поток иссякнет, а юнит-экономика так и не сойдётся — рынок ждёт резкая переоценка.
При чём тут доткомы. Этот сценарий мы уже видели. На рубеже 1999–2000 годов интернет-стартапы оценивались в десятки годовых выручек, которых у многих просто не было. Когда музыка остановилась, индекс Nasdaq рухнул примерно на 78% — с пика весной 2000-го до дна осенью 2002-го, испарив порядка 5 триллионов долларов рыночной стоимости. Pets.com, Webvan, Boo.com и сотни других сгорели дотла.
Но вот что важно для нашей истории: сама технология пузырём не была. Под шумок надувшегося рынка проложили тысячи километров оптоволокна и построили дата-центры, которые потом годами питали уже настоящий бум. А сильнейшие — Amazon, Google, eBay — пережили крах и именно на расчищенном поле выросли в гигантов. Знаменитая формула той эпохи: «Интернет не был пузырём — пузырём были интернет-акции». Сегодняшний аналог переинвестирования — это безумные капзатраты на GPU и дата-центры под ИИ.
Нюанс, без которого нечестно. У прогноза ЛеКуна есть важный контекст: он сам — заинтересованная сторона. Недавно он ушёл из Meta и основал стартап AMI Labs, который в марте 2026-го привлёк 1 миллиард долларов — крупнейший «посевной» раунд в истории Европы. Его ставка — «world models» (модели мира) как альтернатива большим языковым моделям, на которых построены как раз OpenAI и Anthropic. То есть человек, предрекающий проблемы LLM-лабораториям, сам строит конкурента LLM-парадигме. Это не отменяет его аргументов, но заставляет читать их как одновременно диагноз и заявку.
Вывод. ЛеКун почти наверняка не говорит, что «ИИ — это фейк». Речь о другом: о коррекции, которая по аналогии с доткомами вымоет слабых игроков и раздутые оценки, но оставит в живых инфраструктуру и сильнейшие лаборатории — и именно они построят следующую эпоху. Технология реальна; уязвимы — конкретные ценники и бизнес-модели. Главный неизвестный здесь не «лопнет или нет», а «когда»: пузыри славятся тем, что надуваются куда дольше, чем кажется разумным, — и сдуваются ровно тогда, когда в них перестают верить.
Показать полностью
DeepSeek впервые взял внешние деньги — $7,4 млрд при оценке выше $50 млрд. Самый дорогой ИИ-стартап Китая

Китайский стартап DeepSeek впервые за свою историю взял внешние деньги — и сразу рекордно. Раунд более чем на 50 млрд юаней (около $7,4 млрд) оценивает компанию выше $50 млрд (по данным Reuters — $52–59 млрд) и делает её самой дорогой ИИ-компанией Китая. Разбираемся, кто это, как они дошли до такой оценки, чем зашли в опенсорс и почему над ними висит тень обвинений OpenAI.
Кто такие DeepSeek. Компанию из Ханчжоу основал Лян Вэньфэн — он же создатель квантового хедж-фонда High-Flyer. До этого года DeepSeek не брал ни юаня стороннего капитала и жил целиком на деньги фонда. Мировую известность стартап получил в начале 2025-го с моделью R1: она показала уровень топовых западных систем при кратно меньших затратах на обучение — и на этом фоне на день просели акции американских техов, а Вашингтон заново заспорил, достаточно ли экспортных ограничений на чипы.
Прошлые раунды — точнее, их отсутствие. Это вообще первый внешний раунд DeepSeek. Ещё в апреле в кулуарах называли скромные цифры — около $300 млн при оценке $10 млрд. За пару месяцев планка прыгнула в пять раз. Все предыдущие годы исследования финансировал лично Лян через High-Flyer, принципиально не пуская венчурный капитал.

Деньги с подвохом: контроль остаётся у основателя. Структура раунда необычная: внешние инвесторы заводят капитал не напрямую в DeepSeek, а в партнёрство под управлением Ляна — без права голоса и с 5-летней заморозкой. Сам Лян вложил больше всех, около $3 млрд (примерно 20 млрд юаней), оставшись полным хозяином компании. Единственное исключение — китайский госфонд «Big Fund» (National AI Industry Investment Fund): он зашёл напрямую с правом голоса и без локапа. Среди внешних инвесторов — Tencent и производитель батарей CATL.
Ставка на опенсорс и демпинг. Репутацию DeepSeek строит на открытых весах: после V3 и R1 в апреле 2026-го вышла V4 — крупнейшая на сегодня open-weights модель, работающая на чипах Huawei. Плюс агрессивный демпинг: компания сделала скидку 75% на V4 Pro постоянной — по входу это примерно в 11 раз, а по выходу в 35 раз дешевле, чем GPT-5.5 от OpenAI. Лян прямо говорил инвесторам, что ставит фундаментальные исследования и путь к AGI выше краткосрочной прибыли и продолжит выпускать открытые модели.
Тень обвинений OpenAI. При этом с самого взлёта DeepSeek преследуют претензии OpenAI. Ещё в январе 2025-го, сразу после релиза R1, OpenAI заявила, что видит «свидетельства» неправомерной «дистилляции» — когда чужую модель обучают на выводах более мощной, что прямо запрещено правилами OpenAI. Спецсоветник Белого дома по ИИ Дэвид Сакс говорил о «существенных доказательствах». А в феврале 2026-го OpenAI пошла дальше — в меморандуме в Комитет Палаты представителей по Китаю обвинила DeepSeek в «паразитировании» на достижениях американских лабораторий: якобы сотрудники через сторонние роутеры маскировали источник и программно выкачивали выводы западных моделей. Сама DeepSeek обвинения не подтверждала.

Всё равно карлик рядом с гигантами. $50 млрд — рекорд для Китая, но на фоне западных лидеров это скромно: xAI Илона Маска оценивают примерно в $230 млрд, OpenAI — около $852 млрд, а Anthropic в конце мая 2026-го закрыл раунд на $65 млрд и вырвался вперёд с оценкой почти $965 млрд. Новые деньги DeepSeek планирует пустить на исследования и расширение собственных вычислительных мощностей — особенно актуально на фоне санкций, режущих Китаю доступ к топовым американским чипам.
🔗 Источник: The Next Web · НЕЙРО-ПУШКА ● Новости и обзоры нейросетей
Показать полностью
2
Odyssey привлёк $310 млн на ИИ, который строит целые миры. Деньги дали Amazon, Nvidia и AMD

ИИ давно умеет рисовать картинки и монтировать ролики. Но следующая крупная ставка индустрии — не контент, а целые миры. И в эту ставку только что влили $310 миллионов.
Сделка, в которой сошлись конкуренты. Стартап Odyssey закрыл раунд Series B на $310 млн при оценке $1.45 млрд (всего привлечено $337 млн с момента основания в 2023 году). Удивительна тут не сумма, а состав инвесторов: чек выписали венчурные подразделения Amazon, Nvidia и AMD одновременно — три кита облаков и чипов, которые обычно бьются друг с другом, здесь поставили на одну компанию. Среди прочих — фонд GV, главный научный сотрудник Google Джефф Дин, Элад Гил, Гэрри Тан и сооснователь Cruise Кайл Фогт.
Что такое world models. Это не генератор кадров. Odyssey строит модели, которые симулируют физический мир в 3D: «Они понимают физику, язык тела и динамику — то, что языковые модели схватить не могут», — объясняет CEO Оливер Кэмерон. Грубо говоря, вместо предсказания следующего слова такая модель предсказывает, что произойдёт в пространстве дальше.
Откуда берутся данные. Самое любопытное — как Odyssey учит свои модели. Компания отправляет людей с камерами-сферами обходить реальные локации и снимать мир со всех сторон — методология, прямо напоминающая сбор данных для Google Earth. Модели затем оптимизируют под чипы AWS Trainium (Amazon стал основным облаком стартапа).
Кто за штурвалом. Команда из 55 человек с офисами в Лондоне, Цюрихе и Пало-Альто. Основатели пришли из беспилотных авто: CEO Оливер Кэмерон ранее запустил Voyage (поглощён Cruise) и был там вице-президентом по продукту, CTO Джефф Хоук — инженер британского self-driving стартапа Wayve. Логика понятна: научить ИИ симулировать дорогу и научить его симулировать мир — задачи одного класса.
Почему это важно. World models всё чаще называют следующим рубежом ИИ — за пределами языковых моделей. Глава ИИ в Meta Ян Лекун и гендиректор Google DeepMind Демис Хассабис считают их необходимым шагом к настоящему искусственному интеллекту: модели, которая понимает физику и пространство, а не просто жонглирует текстом. Ближайшее применение приземлённее — видеоигры, кино и тренировка роботов в симуляции, где можно прогнать миллион сценариев без единой реальной поломки.
Показать полностью
Битва нейросетей-озвучки: какой TTS лучший для русского дубляжа, честный тест
Делаю пайплайн автодубляжа: на входе англоязычный ролик — на выходе русская озвучка тем же голосом. Сердце такого пайплайна — нейросеть клонирования голоса (voice-clone TTS). Главный вопрос: какую взять?

Можно ткнуть в первую попавшуюся с хайпом. А можно собрать топовые движки и устроить им честную битву на одинаковых условиях. Выбрал второе — прогнал финалистов через 627 семплов. Итоговый рейтинг — в карусели ниже, а вся подноготная (с чего начинали, кого выгнали и почему) — под ней.
Как собирал участников
Брал не наугад, а по реальным лидербордам (TTS Arena, Artificial Analysis) — только свежие флагманы. Часть кандидатов отсеялась сразу на входе: VibeVoice умеет только стриминг, OpenAudio S1 — прошлогодний, IndexTTS-2 — русский сломан, Step-Audio — только англ/кит. Осталось 8 движков для реального прогона.
Методология
Каждому движку — 114 фраз, всего 627 семплов. Тесты: русский и английский, длинные реплики, числа (прописью и цифрами), аббревиатуры (СДВГ, ОКР), иностранные слова, имена, скороговорки, смесь языков. И главное — cross-lingual: английский голос читает русский текст. Это и есть дубляж.
Оценивал на слух, семантически: засчитано всё, что произнесено верно. Если распознавалка записала «десять» как «10», а «Stable Diffusion» как «стейбл дифьюжн» — это её косяк, а не движка: зритель-то слышит правильно. Метрики: разборчивость, похожесть голоса, утечка латиницы, скорость, VRAM, вес на диске. Итоговый балл взвесил под задачу дубляжа.
Двоих выгнали сразу
После предварительного прогона вылетели двое:
dots.tts — на женском голосе разваливался: вместо русского текста выдавал английскую кашу или просто тишину. Плюс самый медленный. На вылет.
Chatterbox — умеет только режим без транскрипта, говорит с заметным акцентом, по сумме не конкурент. Тоже за борт.
Осталось 6 финалистов — детально по каждому в карусели выше, тут коротко:
Финалисты
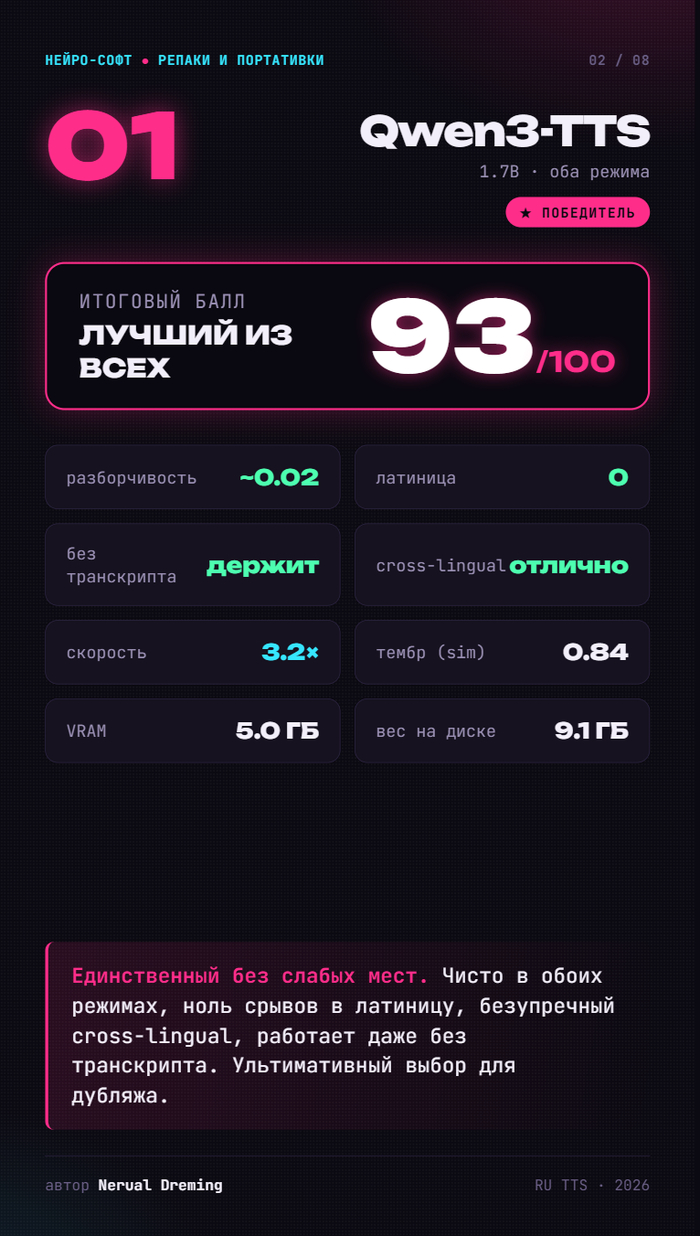
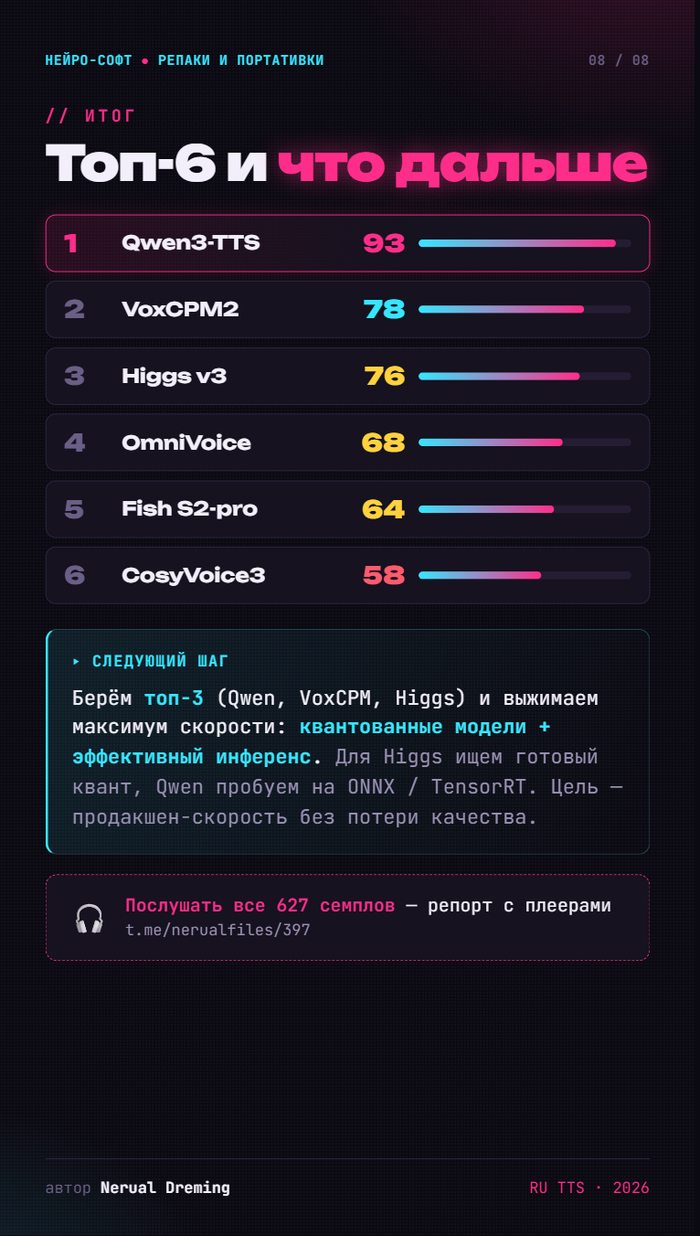
🥇 Qwen3-TTS — 93/100. Чемпион. Единственный без слабых мест: чистая речь и с транскриптом, и без, ноль срывов в латиницу, безупречный cross-lingual, быстрый. Его и берём.
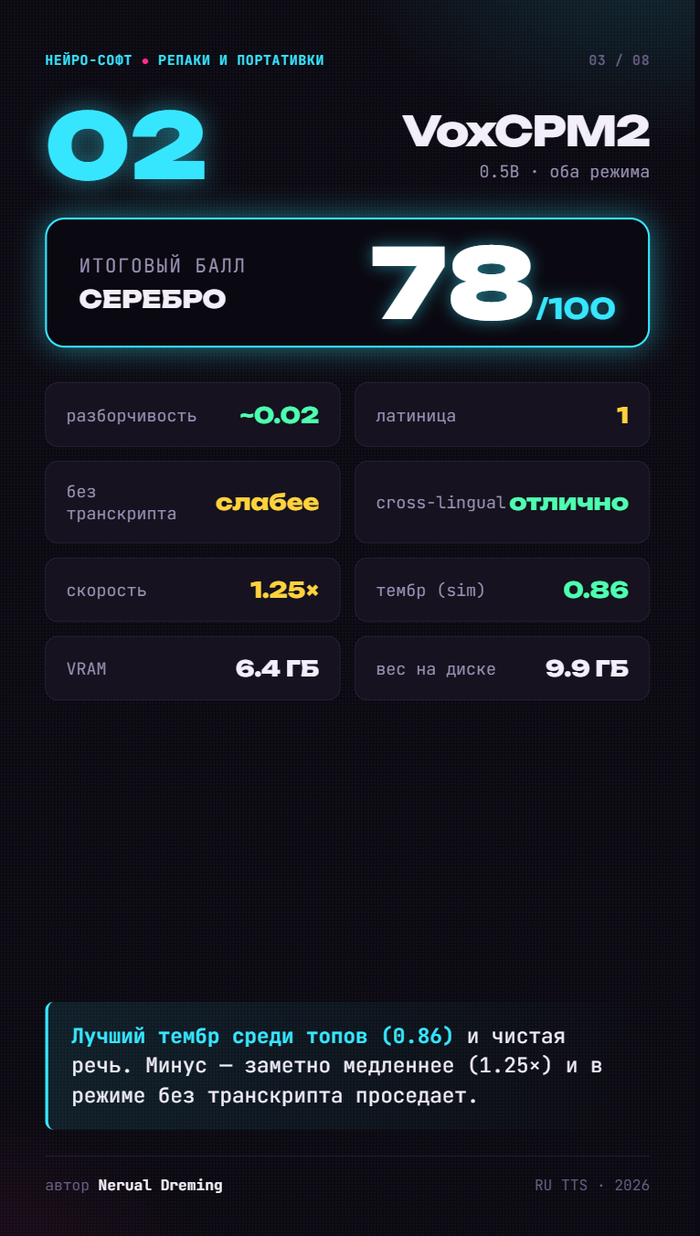
🥈 VoxCPM2 — 78. Лучший тембр среди топов, чистая речь. Минус — медленный и без транскрипта проседает.
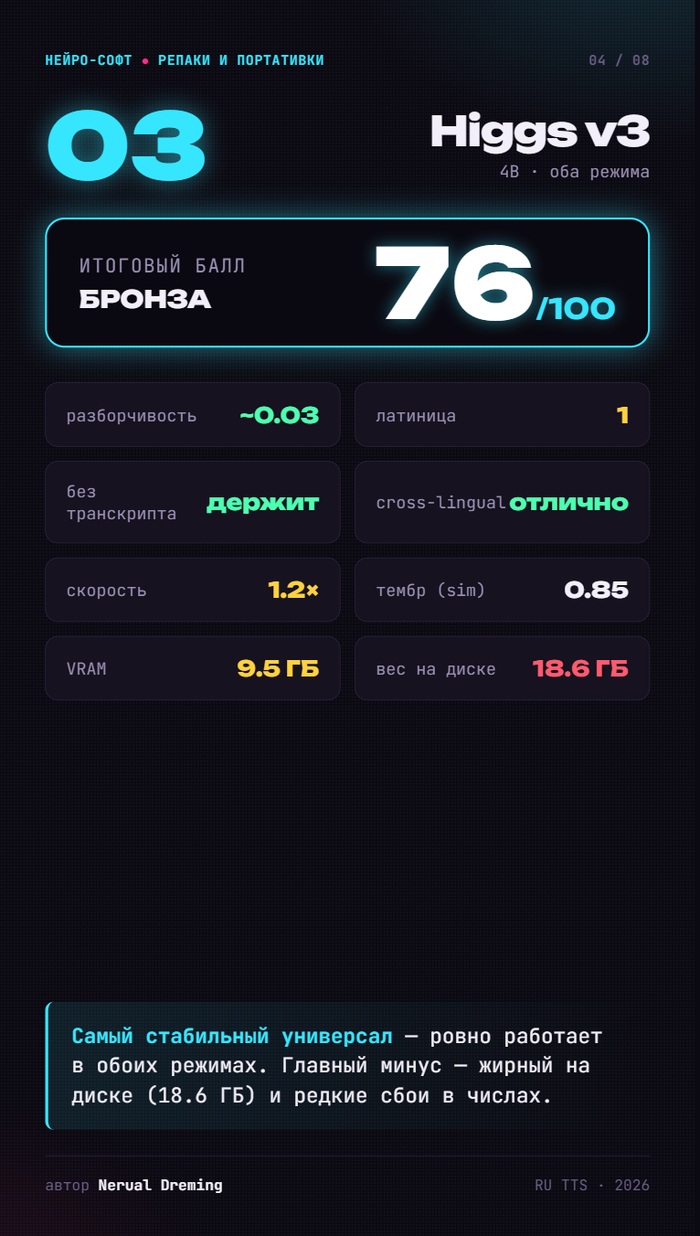
🥉 Higgs v3 — 76. Самый стабильный универсал. Главная беда — 18.6 ГБ на диске.
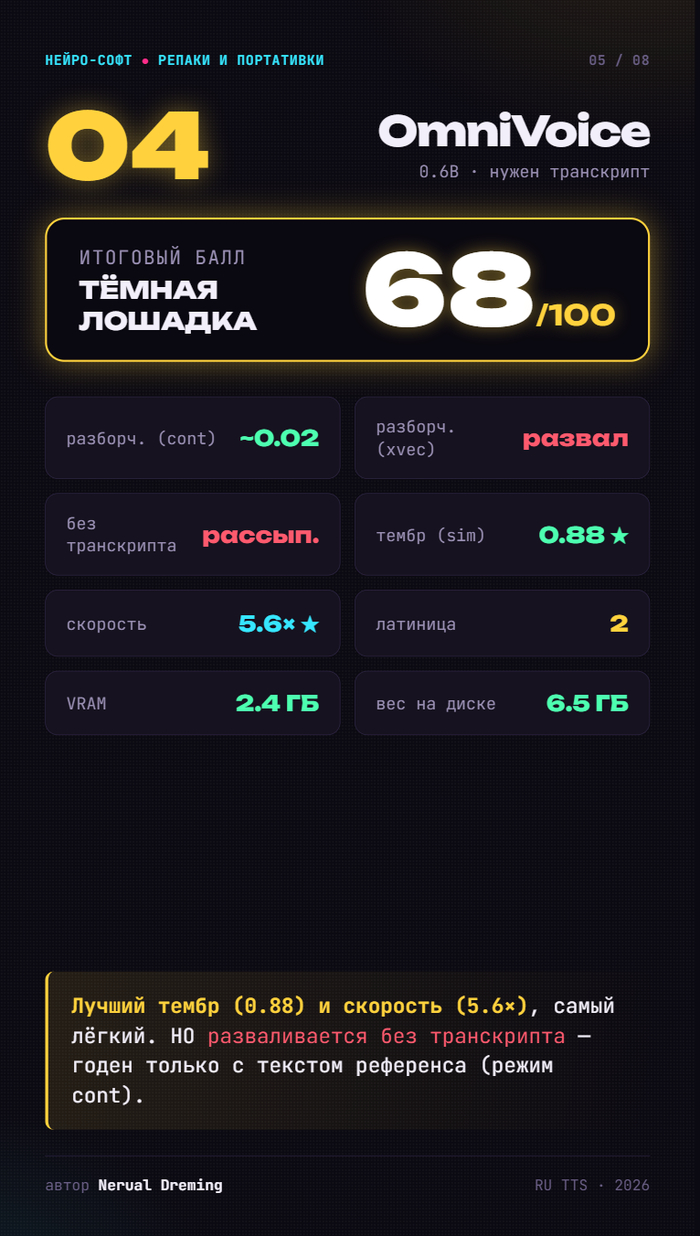
OmniVoice — 68. Тёмная лошадка: лучший тембр (0.88) и самый быстрый (×5.6 от реалтайма), легчайший. НО разваливается без транскрипта — годен только с текстом референса.
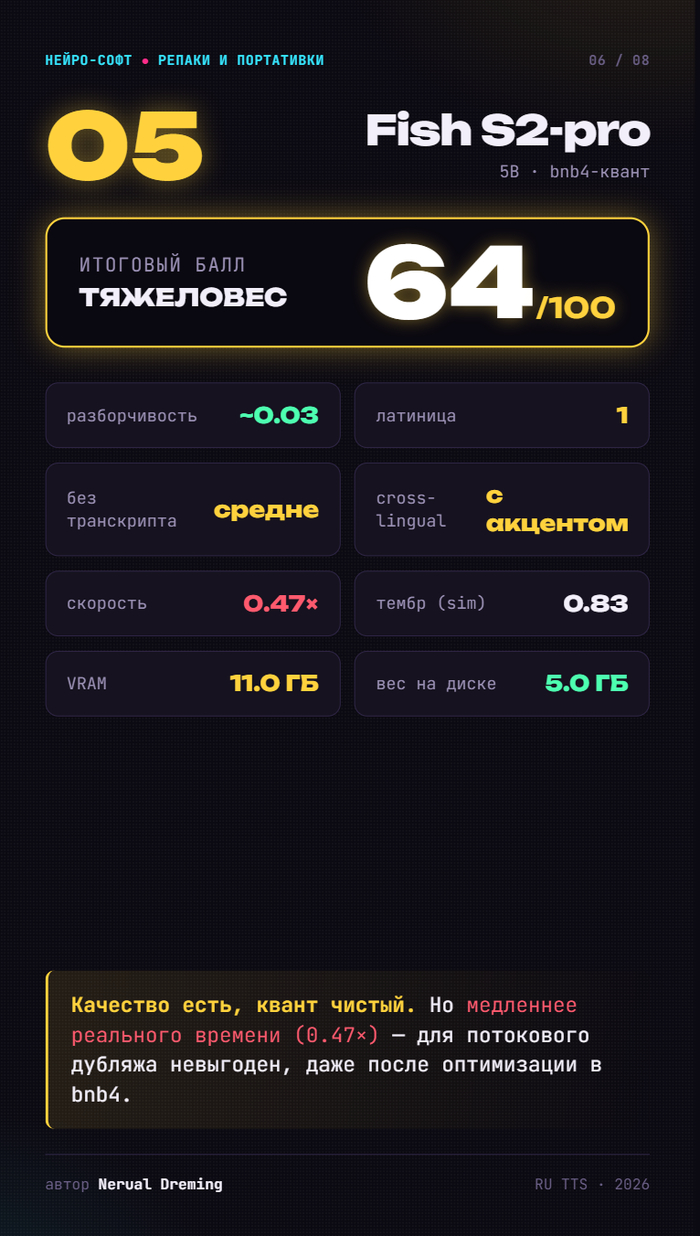
Fish S2-pro — 64. Качество есть, но медленнее реального времени даже после оптимизации. Для потока невыгоден.
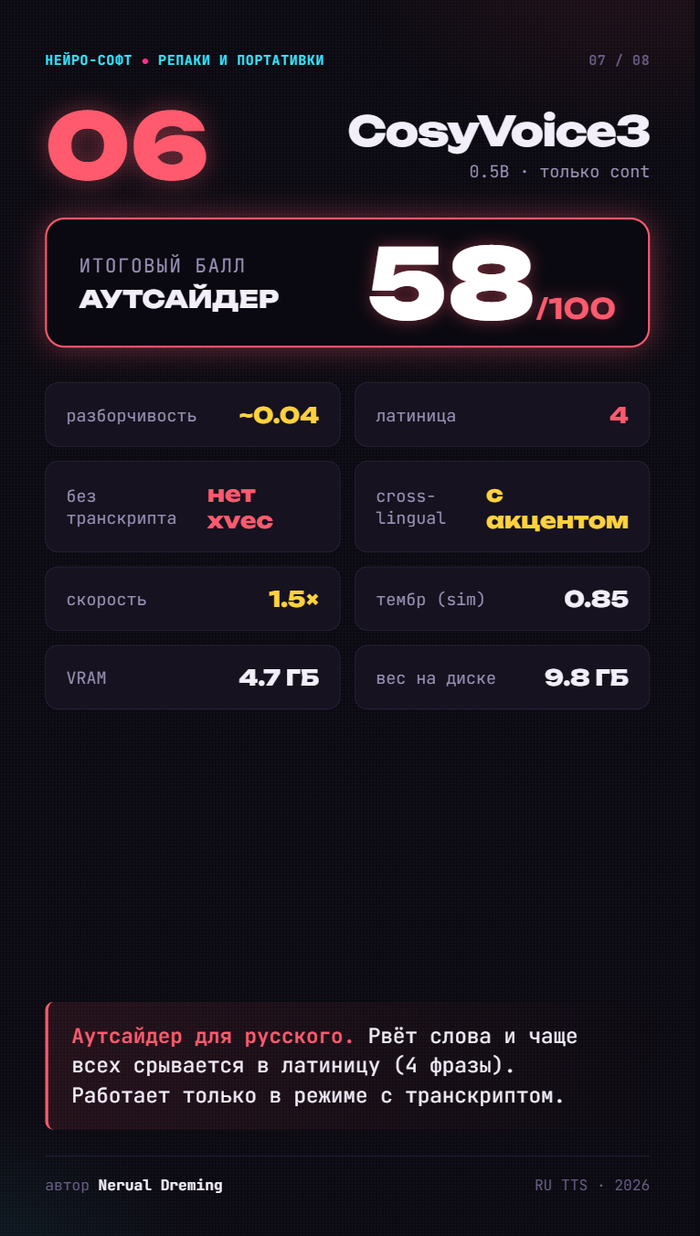
CosyVoice3 — 58. Аутсайдер для русского: рвёт слова и чаще всех срывается в латиницу.
Подводные камни (для технарей)
Fish в полной версии не влезал в 24 ГБ видеопамяти — распухал KV-кэш. Взял квантованную bnb4, сверил с полной по качеству (A/B) — квант оказался чистым.
CosyVoice пробовал ускорить через GGUF — и женский голос зациклился в 82 секунды мусора. Оказалось, баг самого тракта запуска (не доходит до токена остановки), а не квантизации.
Главная ловушка — распознавалка пишет англицизмы кириллицей. Чуть не записал кучу правильных озвучек в брак, пока не пересмотрел каждый транскрипт глазами.
Что дальше
Беру топ-3 (Qwen, VoxCPM, Higgs) и выжимаю максимум скорости: квантованные модели + эффективный инференс. Для Higgs ищу готовый квант, Qwen пробую на ONNX / TensorRT. Цель — продакшен-скорость без потери качества.
🎧 Хотите послушать все 627 семплов сами — собрал отдельный репорт с плеерами: t.me/nerualfiles/397
Это первая часть. В следующей — оптимизирую топ-3 под продакшен: квантованные модели, ONNX, TensorRT — и замерю реальный прирост скорости без потери качества. Будет интересно.
Мой канал: НЕЙРО-СОФТ ● РЕПАКИ И ПОРТАТИВКИ.
Показать полностью
8
SpaceX покупает Cursor за $60 млрд: ракетная компания врывается в войну ИИ-кодинга

SpaceX заплатит $60 млрд за Anysphere — компанию, стоящую за ИИ-редактором кода Cursor. Сделку объявили во вторник, всего через четыре дня после крупнейшего IPO в истории. И она мгновенно ставит вопрос, которым теперь задаётся каждый разработчик: что будет с инструментом, который выбирали именно за независимость от конкретной нейросети?
Как ракетная компания дошла до покупки кодинг-стартапа
Всё началось в феврале 2026-го, когда SpaceX поглотила xAI Илона Маска — на тот момент крупнейшее корпоративное слияние в истории (SpaceX тогда оценили в $1 трлн, xAI — в $250 млрд). В состав вошли чат-бот Grok, соцсеть X и мемфисский суперкомпьютер Colossus — около 555 тысяч GPU с планом разогнаться до миллиона H100-эквивалентов. Получившееся ИИ-подразделение столкнулось с парадоксом: гигантские мощности есть, а продуктов для разработчиков почти нет. При этом xAI закрыл 2025 год с убытком $6,35 млрд, а рынок ИИ-кодинга рос на 65% в год — без него.

Опцион вместо покупки: как Маск перебил венчурных инвесторов
В апреле SpaceX не стала покупать Cursor сразу, а оформила хитрый опцион: либо выкупить Anysphere за $60 млрд до конца года, либо заплатить $10 млрд за совместную разработку. Этим ходом Маск сорвал уже готовившийся раунд Series E на $2 млрд при оценке $50 млрд, который вели Andreessen Horowitz и Thrive Capital — предложив оценку на 20% выше. К тому моменту Cursor уже обучал свои модели Composer на кластере Colossus, а двое его инженеров перешли в xAI ещё в марте.
Сколько стоит Cursor
Cursor — один из самых быстрорастущих программных продуктов в истории: больше миллиона платящих пользователей и годовая выручка, по разным оценкам, от $3 до $4 млрд. Для сравнения: в январе 2025-го стартап оценивали в $2,5 млрд, в ноябре — уже в $29,3 млрд. $60 млрд акциями — это всего 3,4% размытия от капитализации SpaceX на IPO. Если сделка вдруг сорвётся, SpaceX заплатит «отступные»: $1,5 млрд деньгами и $8,5 млрд вычислительными ресурсами.

Зачем это SpaceX и почему нервничают разработчики
Логика — вертикальная интеграция и гонка за лидерами. Маск получает готовый боевой продукт с миллионной аудиторией вместо разработки с нуля и шанс догнать OpenAI и Anthropic, чьи модели стали стандартом «вайб-кодинга». CEO Cursor Майкл Труэлл написал, что рад «масштабировать Composer» — собственную модель компании. Но у медали есть обратная сторона: Cursor ценили именно за то, что он работал на любых моделях — Claude, GPT, собственном Composer. Теперь он принадлежит их прямому сопернику. Слияние пройдёт через дочернюю структуру X67 Inc., закрытие ждут в третьем квартале — при условии одобрения регуляторов.
Показать полностью
2