Вышла новая модель для синтеза речи ZONOS2
Введена новая TTS-модель ZONOS2 (https://huggingface.co/Zyphra/ZONOS2) для работы в реальном времени с высокоточным клонированием голоса под лицензией Apache 2.0.
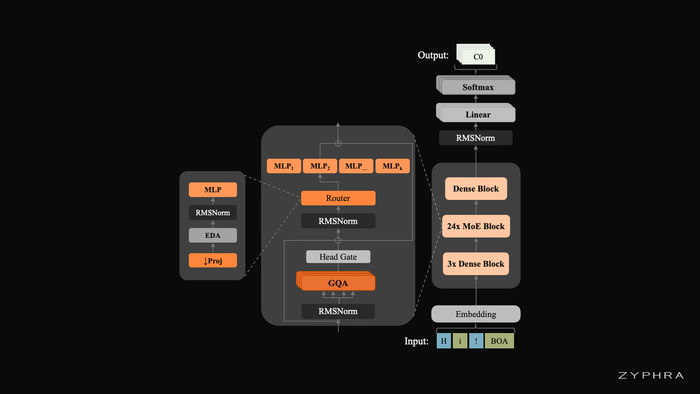
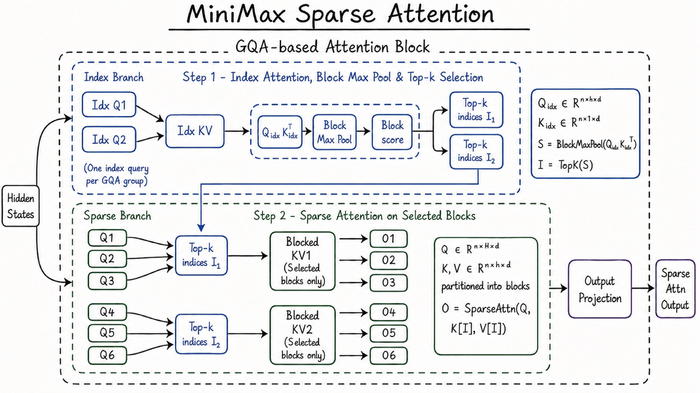
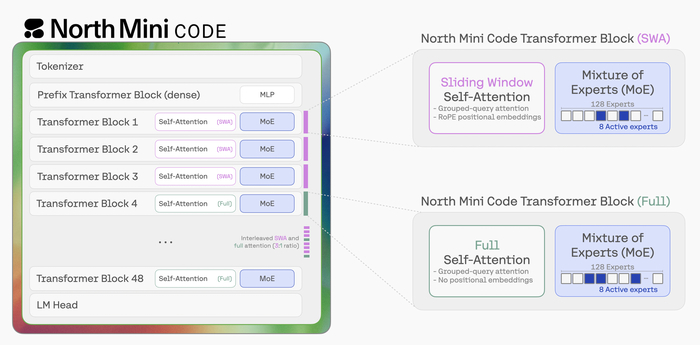
Его разреженный Mixture of Experts (MoE) обладает 8 млрд параметров и 900 млн активных, став первым открытым MoE TTS.
Гибкие настройки дают выбор между "стабильным" (чистый студийный звук) и "экспрессивным" (максимальная верность исходному голосу) режимами.
Обучение осуществлялось на более 6 млн часов аудио с трёхэтапной фильтрацией при постепенном ужесточении требований к согласованности транскриптов.
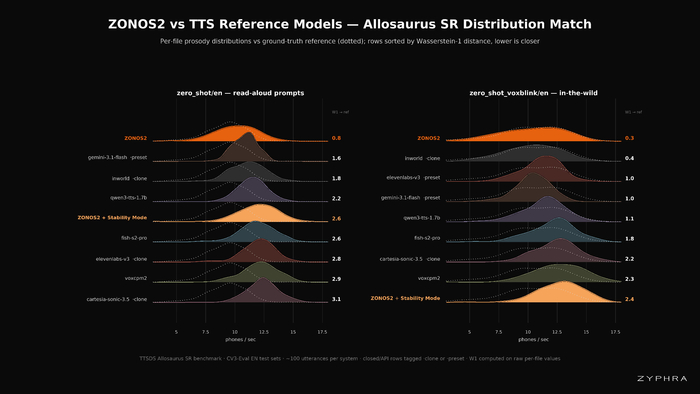
Текст подвергают токенизации в формате сырых UTF-8 байтов без фонемизации. Аудио преобразуют в токены кодека DAC (44.1 кГц), используя автогрессивный паттерн задержки.
Среди настроек есть цифровой отпечаток голоса (ECAPA-TDNN), скорость речи, качественные параметры (полоса, громкость, SNR).
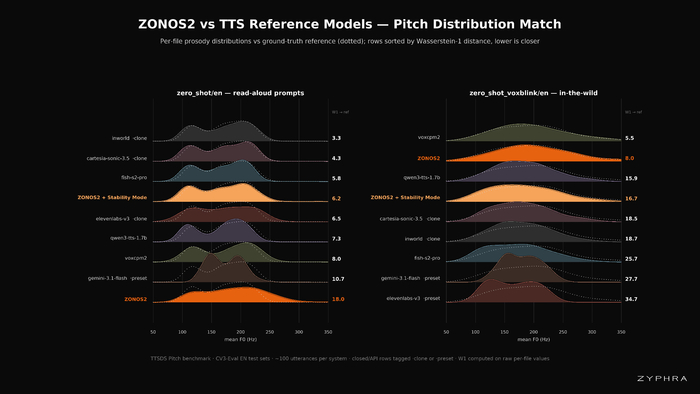
Представленный эталон ZTTS1‑Eval показал чистые (FLEURS‑R) и "дикие" (VoxBlink2) выборки, метрики интонации и ритма (Allosaurus SR, Pitch, DS‑WED), схожесть диктора (ReDimNet) и качества (MSR‑UTMOS, Qwen3‑ASR).
В результате обеспечен 4-кратный прирост скорости против предыдущей версии и качество на уровне ведущих решений.