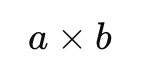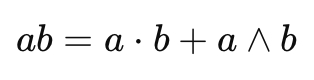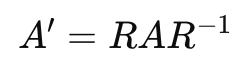Во времена XP, я на её присутствие забивал, ну есть и есть.
Во времена 7-ки меня начал бесить драйвер в пару сотен метров, нахер не нужный, поэтому я написал батник, ставящий null драйвер (что бы диспетчере вопросы не висели и сон работал):
@chcp 1251>nul&&more +1 "%~f0">null_drv.inf &pnputil.exe -i -a "%cd%\null_drv.inf" &del "%cd%\null_drv.inf"
Плагин называется Workout Gate. Он подключается к Claude Code и работает как строгий фитнес-тренер. Перед отправкой промпта он открывает вебку и заставляет делать отжимания, приседания, в зависимости от настроек или можно добавить собственные упражнения. Он считает повторения в реальном времени и пока не выполнишь норму — не пропустит промпт. Если недоделаешь упражнения, к примеру закроешь окно, выйдешь — недоделанные повторения записываются в долг и добавляются к следующему вызову. Нельзя просто закрыть вкладку и наебать систему ))
Есть пресеты, триггеры по времени, рандому, промпту, статистика, рекорды.
Мемный, но рабочий проект для тех, кто хочет совмещать кодинг с физическими тренировками. 😄
Довольно долго читал Пикабу тайком, особенно аниме-сообщество, даже аккаунта не было. Зарегистрировался вот только сейчас, чтобы поделиться своим проектом. Решил, что кому-то это тоже может пригодиться и сэкономит время.
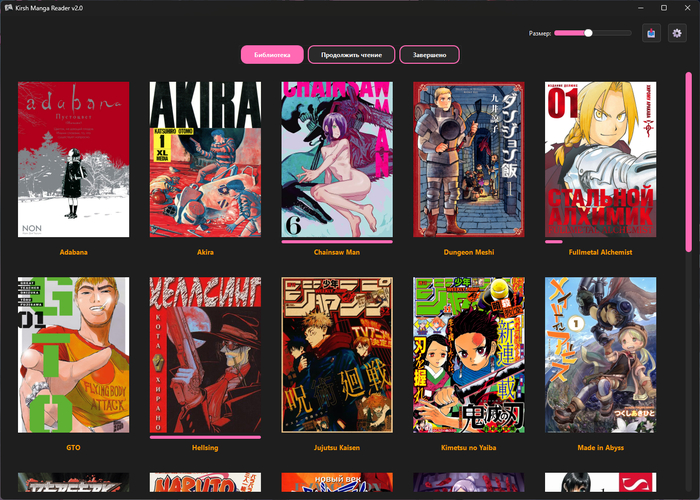
Мне надоело читать мангу в браузере из-за обилия рекламы, а старые программы для компьютера выглядят так, будто их забросили лет пятнадцать назад. Поэтому я сел и написал свое приложение на Python и PyQt6. Назвал его Kirsh Manga Reader.
Делал проект чисто под свои привычки: сначала найти интересную мангу и скачать нужные главы пачкой, потом быстро проверить в приложении, что все файлы на месте, и перекинуть готовую сборку на читалку или полистать прямо с экрана ПК.
Что в итоге получилось сделать по функциям.
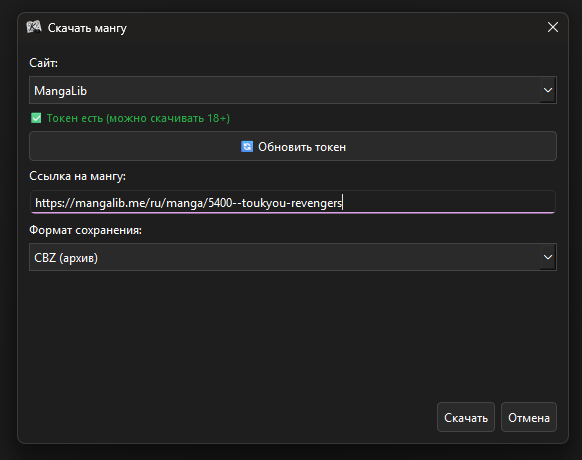
Скачивание глав идет отдельно от интерфейса, поэтому программа не зависает и не тупит в процессе. Сейчас настроил работу с MangaLib и Com-X. Также решена проблема с защитой сайтов от скачивания: приложение через Selenium один раз проходит проверки или авторизацию, забирает куки и дальше спокойно качает файлы на нормальной скорости.
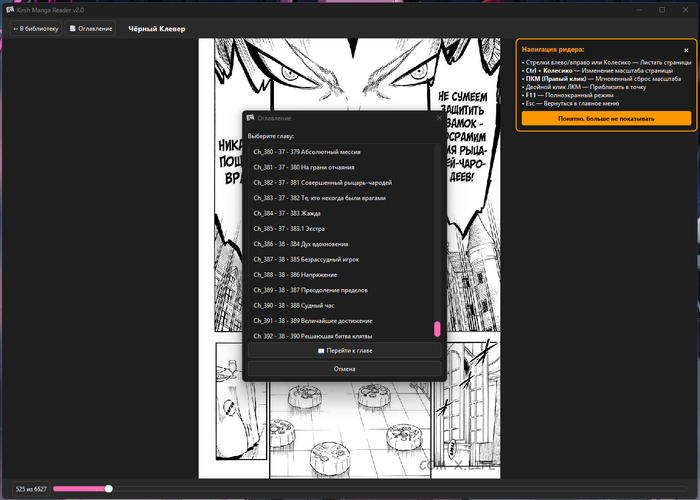
Для самого чтения я использовал графическую сцену PyQt. Страницы можно приближать и двигать мышкой, все работает плавно, без задержек. Прогресс чтения сохраняется автоматически, программа помнит даже конкретное место на странице, где вы остановились.
Но главным испытанием стала сортировка сторонних файлов. Думаю, многие сталкивались: скачиваешь архив с торрента, а там бардак в структуре. В одном месте картинки лежат в корне, в другом запрятаны в три подпапки, а операционная система еще и путает порядок страниц, например, ставит десятую картинку сразу после первой. Я написал алгоритм, который полностью игнорирует пустые папки, находит сами изображения, сортирует их по нормальному порядку и выдает ровное, последовательное оглавление.
Приложением уже можно спокойно пользоваться, но бросать проект я не планирую. В планах добавить поиск по локальной библиотеке, сделать предзагрузку страниц (чтобы следующая страница подгрузилась в память, пока вы читаете текущую), добавить новые сайты и сделать вертикальный режим для удобного чтения манхвы.
Проект полностью бесплатный, без рекламы, код открыт и выложен на GitHub.
Так как я делал все под себя, мне очень интересно узнать мнение других людей. Пишите в комментарии свои пожелания о доработках. Если вам не хватает каких-то конкретных функций или сайтов для скачивания, рассказывайте, я постараюсь добавить это в следующих обновлениях.
Привет, Пикабу! Мне 13 лет, я учу Python и очень хочу в будущем стать инженером в Google AI. Недавно мы с моим AI-помощником выпустили обновление 1.1 для моей первой игры про выживание пушистого Хвостика! Вы играете за питомца, балансируете между сытостью, счастьем и здоровьем, а в финале есть скрытая концовка с золотым ошейником. Для меня этот проект сейчас идеален, потому что всё работает без багов и именно так, как мы задумали! Буду очень рад вашей поддержке, советам в комментариях и звёздочкам на GitHub. Поиграть в квест и заценить сам код версии 1.1 можно прямо в моём репозитории по ссылке: https://github.com
import random
hunger = 50
happiness = 50
hp = 50
print ("привет! ты пушистый хвостик.твоя цель-выжить 5 дней!")
for day in range (1,6):
print(f"День {day} Куда пойдешь?")
print("1 кухня")
print("2 комната с хозяином")
print("гулять на улице с другими хвостиками")
print("4 пойти в магазин с хозяином")
print("5 пойти в городской парк")
print("6 пойти в ветеринарную клинику")
choice = input("Твой выбор:")
if choice == "1":
event = random.randint(0,1)
if event == 0:
print("мама угостила хвостика сыром (^o^)")
hunger += 20
happiness -= 10
else:
print("мама наступила на хвостика (>o<)")
happiness -= 20
hunger -= 10
hp -= 15
bonus_event = random.randint(1,5)
if bonus_event == 5:
print("мама уронила сосиску и хвостик её стащил")
hunger += 15
happiness +=10
hp += 5
elif choice == "2":
event = random.randint(0,1)
if event == 1:
print("хозяин почесал пузико хвостику (^0^)")
happiness += 20
hunger -= 10
else:
print("хозяин спал но забыл вкусняшку на столе (-_-)")
happiness -= 15
hunger += 15
bonus_event = random.randint(1,5)
if bonus_event == 5:
print("хвостик нашел игрушку под диваном")
happiness += 20
elif choice == "3":
event = random.randint(0,1)
if event == 1:
print("хвостик упал и поранился (0_0)")
happiness -= 15
hunger -= 10
hp -= 25
else:
print("хвостик побегал с друзьями (^o^)")
happiness += 25
hunger -= 15
elif choice == "4":
event = random.randint(0,1)
if event == 1:
print("хвостик пошел в магазин с хозяином и спокойно себя вел(=_=)")
hunger -= 10
happiness += 15
else:
print("хвостик украл палку колбасы(>D<)")
hunger += 10
happiness -= 15
elif choice == "5":
event = random.randint(0,1)
if event == 1:
print("хвостик встретил друзей в парке и его угостили вкусняшкой(^-^)")
hunger += 10
happiness += 20
else:
print("хвостик никого не встретил и на хвостика напала стая собак(T_T)")
hunger -= 5
happiness -= 0
hp -=40
elif choice == "6":
event = random.randint(0,1)
if event == 1:
print("хвостик пришел к ветеринару и ему поставили укол(>_<)")
happiness -= 20
hp += 50
else:
print("ветеринар дал витаминку(")
hunger += 10
happiness += 10
hp += 15
print(f" конец дня.Сытость{hunger}/Счастье:{happiness}/Здоровье:{hp}")
if hunger <= 0 or happiness <= 0 or hp <= 0:
print("хвостик проиграл")
exit()
print("хвостик прожил 5 дней и стал супер хвостиком")
final = input("ты нашел золотой ошейник!1-надеть,2-отдать хозяину").strip()
Стоит открыть исходники любого современного игрового движка – неважно, это C++-рендер, сделанный на коленке, или какая-нибудь гигантская экосистема вроде Unity или Unreal Engine – вы первым делом натыкаетесь на одни и те же знакомые сущности. Все вокруг живет в Vector3: координаты, направления движения, точки столкновений. Каждая частица указывает, куда она смотрит, с помощью Quaternion. А если требуется что-то покруче – переносить и одновременно крутить объект, то Matrix4x4. Это уже как стандарт де-факто: кто пробовал крутить объекты руками, тот точно переписывал код с этими структурами. Ещё конечно же отдельно существуют лучи, плоскости, сферы, bounding boxes, а между ними тянутся километры функций вроде dot(), cross(), normalize(), lookAt(), inverse(), project() и бесконечных преобразований типов.
Привыкаешь к этому быстро. Нам кажется совершенно естественным тасовать эти типы между собой – уж слишком давно так делается по всей индустрии. Но стоит лишь чуток задуматься, и начинает прорезаться легкий когнитивный диссонанс: выходит, вся наша графика построена на наборах несовместимых между собой математических запчастей. Для одного действия нам нужен один тип данных, для второго – другой, а пересчитать простое столкновение луча со сферой или плоскостью без пятого велосипеда никак не получается. Вроде бы всё работает и даже неплохо работает… Но ощущение конструктора из костылей не отпускает.
И самое интересное заключается в том, что так было не обязательно.
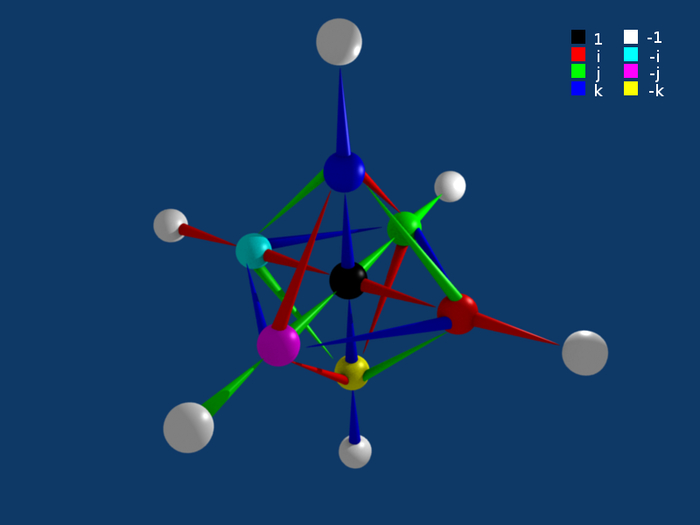
И тут интересно вспомнить XIX век. Тогда математики как раз ломали головы над тем, чтобы придумать нормальный универсальный язык для описания пространства – не мелочиться кучей частных формул на каждый случай жизни. William Rowan Hamilton придумывает кватернионы: компактный инструмент для вращений в пространстве, который становится сегодня основой всей компьютерной анимации (даже те же Unity и Unreal ими внутри манипулируют).
Графическое представление таблицы умножения базисных кватернионов (цвет шара определяет первый множитель, цвет выходящей стрелки – второй множитель, стрелка указывает на результат умножения)
Параллельно Hermann Grassmann выносит мозг коллегам идеей: почему бы алгебре не оперировать сразу плоскостями и объемами целиком? Ну действительно: мы привыкли складывать числа и векторы, а как быть с более сложными сущностями? Дальше подключается William Kingdon Clifford, собирает всё это в одну систему – получает Геометрическую Алгебру.
По сути, Клиффорд пытался создать универсальную операционную систему для геометрии.Но индустрия пошла другим путем.
Когда физикам и инженерам понадобилась удобная математика для электромагнетизма и механики, Josiah Willard Gibbs и Oliver Heaviside взяли идеи Клиффорда и разрезали их на части. Из цельной алгебры были извлечены только самые прикладные куски – скалярное и векторное произведения. Так появился привычный нам vector calculus, который сегодня преподают во всех технических вузах и используют почти все графические API.
Фактически современная графика работает не на полной геометрической теории, а на ее урезанной инженерной версии. Проблема этой урезанности особенно хорошо видна на векторном произведении. Все знают формулу:
Она дает вектор, перпендикулярный двум другим. На ней построены нормали, вращения, ориентация треугольников и половина графического пайплайна. Но есть неприятный нюанс: эта операция нормально существует только в трехмерном пространстве. В двумерном мире полноценного векторного произведения нет вообще, а в четырехмерном результат уже перестает быть обычным вектором. То есть одна из фундаментальных операций всей 3D-графики – это математический хардкод под конкретное число измерений.
Клиффорд предложил гораздо более общую идею. Вместо отдельного скалярного и отдельного векторного произведения он ввел единую операцию:
На первый взгляд формула выглядит странно. Слева произведение двух векторов, справа сумма каких-то совершенно разных объектов. Но именно здесь скрывается главная идея Геометрической Алгебры.
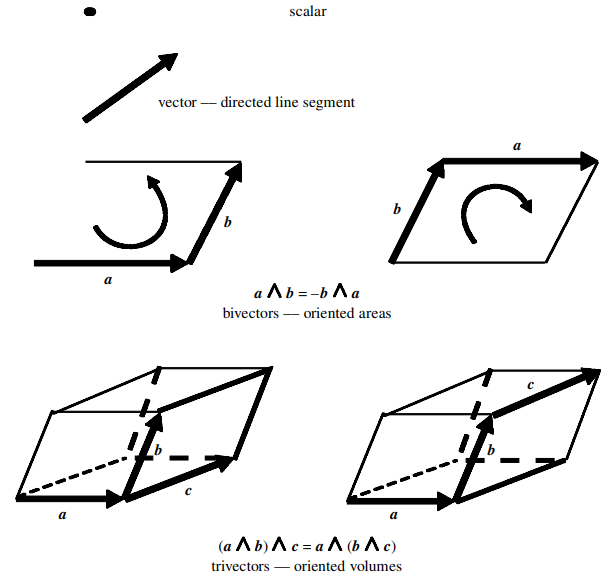
Первая часть привычное скалярное произведение. Число. Ничего нового. А вот – это внешнее произведение Грассмана. И его результатом является не вектор, а новый геометрический объект – бивектор.
Бивектор очень трудно понять, если смотреть на него через призму привычной линейной алгебры. Нас с детства учили, что результат взаимодействия двух векторов – это либо число, либо еще один вектор. Но Грассман предложил мыслить иначе. Если два вектора натягивают параллелограмм, то естественным результатом их комбинации должна быть сама ориентированная площадь этого параллелограмма. Не стрелочка, торчащая перпендикулярно плоскости. А сама плоскость.
Бивектор хранит площадь и ориентацию обхода. По сути, это элемент поверхности. Вот тут у многих мир переворачивается: оказывается наше привычное векторное произведение («дай-ка найду нормаль к плоскости») – это такой засекреченный хак ради удобства старой учебной математики! Мы подсознательно заменяем настоящую плоскость перпендикулярным ей вектором просто потому, что так проще считать по старинке. Но Геометрическая Алгебра говорит: зачем вообще выбрасывать информацию о самой плоскости?
В итоге из этой идеи рождается целая лестница геометрических объектов: есть значение (число), есть направление (вектор), есть площадь (бивектор), есть объем (тривектор) – все это элементы единой структуры под капотом! У людей технических такое вызывает лёгкое недоверие («подожди… какой еще вектор-площадь?») – словно кто-то предлагает напрямую сложить яблоки с квадратными метрами. Но идея-то именно в этом: собрать всю геометрию пространства под одной крышей, чтобы перестать тащить за собой гору несовместимых матрешек.
А затем появляется самая странная и одновременно самая мощная концепция – мультивектор. А дальше начинается магия серьёзной математики. Стоит расширить наше 3D-пространство до пятимерного (!) за счет двух спец-направлений – одно станет отвечать за начало координат вселенной, другое символизирует бесконечность во всех смыслах слова. Получаем Conformal Geometric Algebra (CGA): звучит максимально экзотично и сначала похоже на сугубо теоретические упражнения… Но вот что удивительно: CGA позволяет описывать сферы, окружности и прочие объекты как такие же элементы своей алгебры так же естественно, как вы оперируете обычными точками или прямыми.
Выглядит всё это так будто из учебника магии для программиста. На практике же происходит нечто почти магическое: все геометрические объекты начинают описываться одинаково.Точка становится мультивектором. Сфера становится мультивектором. Плоскость тоже становится мультивектором. Причем в CGA плоскость фактически является сферой бесконечного радиуса. Это уже не отдельный тип сущности, а частный случай более общего объекта.
Для программиста это звучит почти еретически. Представьте движок, в котором Plane, Sphere, Ray и Lineперестают быть независимыми структурами и становятся вариациями одной и той же геометрической сущности. Но самое важное начинается дальше.
Сегодня практически любой физический движок содержит десятки специализированных функций:
Каждая написана отдельно. У каждой свои edge cases. В каждой свои проверки на epsilon, вырожденные случаи и численные артефакты.
В CGA идея совершенно другая: пересечение – это не набор специальных алгоритмов, а базовая операция самой алгебры. Вместо огромного набора формул появляются универсальные операции вроде внешнего произведения или операции Meet. Геометрия начинает выглядеть не как коллекция инженерных костылей, а как цельная система преобразований. Еще более радикально это проявляется в трансформациях.
Современная графика использует целый зоопарк представлений. Повороты кодируются кватернионами. Переносы – матрицами. Масштабирование – другими матрицами. Для анимации часто добавляются dual quaternions. Внутри движка постоянно происходит конвертация между разными представлениями одной и той же геометрии.
В CGA все это заменяется единым объектом – ротором. Любое преобразование записывается одинаково:
И неважно, что именно делает RR. Если он кодирует вращение – объект повернется. Если перенос – объект сдвинется. Если масштаб – масштабируется. Формула остается одной и той же.
Для человека, который годами писал графический код, это выглядит почти незаконно. Особенно впечатляет то, как меняется сам стиль программирования. Например, в библиотеке clifford код начинает напоминать скорее школьную геометрию, чем традиционный graphics programming:
from clifford.g3c import *
# Создаем две точки в конформном пространстве point1 = up(eo + 1*e1) point2 = up(eo + 5*e1)
# Линия - это просто внешнее произведение двух точек и бесконечности line = point1 ^ point2 ^ einf
# Сфера с центром в point1 и радиусом r r = 2.0 sphere = point1 - 0.5 * (r**2) * einf
# Ищем пересечение линии и сферы. ОДНА СТРОЧКА! intersection = line.meet(sphere)
В этом фрагменте почти шокирует отсутствие привычных вещей. Нет матриц. Нет ручной тригонометрии. Нет вызовов cos() и sin(). Нет километров условий вроде if(dot < 0). Код начинает выражать не алгоритм вычисления, а саму геометрическую идею. Именно поэтому многие люди, впервые столкнувшиеся с GA, испытывают странное чувство. Возникает ощущение, будто вся современная 3D-графика десятилетиями решала геометрические задачи окольным путем.
Но тогда возникает очевидный вопрос: если Геометрическая Алгебра настолько красива, почему индустрия до сих пор массово не перешла на нее?
Потому что у этой красоты есть цена. Главная проблема – производительность. В конформной алгебре мультивектор в 5D содержит коэффициента. Для сравнения: обычный Vector3 хранит всего три числа. То есть даже простая точка внезапно становится огромной структурой данных. Для CPU-кэша и особенно для GPU это настоящая катастрофа.
Современные видеокарты десятилетиями оптимизировались под операции над четырехкомпонентными векторами и матрицами 4×4. Под них существуют SIMD-инструкции, специализированные блоки вычислений, драйверы и шейдерные пайплайны. Вся индустрия буквально выращена вокруг матричной математики. GA пока остается чужаком на этом празднике жизни.
Есть и другая проблема – психологическая. Геометрическая Алгебра требует полностью перестроить мышление. Разработчик должен отказаться от привычной модели вектор + матрица + кватернион и начать воспринимать геометрию как единую алгебраическую систему. Это не просто новая библиотека. Это почти смена языка мышления.
И все же GA постепенно просачивается в области, где математическая устойчивость важнее, чем каждый такт процессора. В робототехнике она позволяет решать задачи обратной кинематики без многих классических сингулярностей. В компьютерном зрении упрощает работу с проекциями и геометрией камер. В физических симуляциях делает системы ограничений гораздо более естественными.
Самое интересное, что индустрия может прийти к Геометрической Алгебре не через университеты, а через компиляторы. Уже появляются генераторы кода, которые умеют анализировать мультивекторы на этапе сборки, выкидывать нулевые коэффициенты и превращать красивые абстрактные формулы в очень эффективные SIMD-инструкции. То есть разработчик пишет чистую геометрию, а компилятор превращает ее в быстрый машинный код.
И тогда возникает неприятная мысль. Возможно, вся современная архитектура 3D-движков с матрицами, кватернионами и бесконечными специализированными пересечениями – является не вершиной эволюции, а историческим компромиссом, который случайно закрепился на сто лет.
Возможно, правильная математика для графики была придумана еще в XIX веке. И мы только начинаем к ней возвращаться.
Загадочная микросхема ME и для чего Intel ставит её в материнские платы
С далёкого 2008 года и до сегодняшних дней во все чипсеты на базе intel встроена интересная микросхема, которая называется Intel Management Engine. Про данную систему известны некоторые факты, которые очень понравятся любителям теории заговоров, каждый для себя из этих сведений сможет сделать свой вывод.
Факт первый: работает когда компьютер выключен Intel ME это микросхема, которая встроена в северный мост материнской платы компьютера (на новых платах в PCH). За счёт дежурного напряжения, подаваемого на чипсет, на эту микросхему подаётся питание даже тогда, когда компьютер выключен.
Факт второй: как работает — большой секрет Программа, работающая с микросхемой, находится в закрытой области BIOS и зашифрована. Сама микросхема имеет нетипичную архитектуру. Функции этой системы Intel не документирует. А прошивка ещё и дополнительно запутана.
Факт третий: у неё прямой доступ к сети Система имеет прямой доступ к сетевой карте, а микросхема отдельный MAC адрес, что уже наводит на мысли. Более того, каждый бит данных входящий в сетевую карту компьютера из интернета в обход windows передается в intel me...
Факт четвертый: подозревают давно Фонд электронных рубежей - известная правозащитная организация, уже давненько обвинила intel в том, что в их чипсете содержится троян, который может давать доступ к любому компьютеру в мире. Но так никто и не показал полную документацию на микросхему.
Факт пятый: её невозможно отключить Существовали прошивки умельцев в которых чип был отключен, но компьютер на таких прошивках работал нестабильно. Вместе с отключением микросхемы урезалась часть полезных функций. К тому же, теперь intel перенесли в ME часть функций BIOS, что ещё сильнее затруднило отключение системы. Некоторые экспериментаторы отключали чип програмно, но получали довольно странную ошибку, в следствии которой компьютер выключался ровно через пол часа работы. Срабатывал так называемый watch dogs timer.
Факт шестой, её развивают и улучшают Как я уже писал выше, часть функций из BIOS, например ACPI (отвечает за кулеры, оверклокинг и много чего еще) была перенесена в intel me. Кроме того в новых сериях чипсетов была добавлена поддержка NFC и Wi-Fi.
Факт седьмой Intel является стратегическим партнёром АНБ. Ну может кто не знал...
Выводы Официально компания заявляет, что intel me нужна для стабильности и повышения производительности системы. Очень туманное на мой взгляд объяснение.
Довольно удобно переложить важные функции ПК из BIOS в микроконтроллер с незадокументированной архитектурой и зашифрованной программой. Делая, таким образом, эту микросхему обязательной для использования и абсолютно неконтролируемой для пользователя.
Для чего это нужно - (пока не понятно). Интересно будет послушать ваши версии...
В серверной разработке на Python, аналитике данных и задачах автоматизации офисной работы чтение файлов Excel и преобразование их в удобные для программ обработки структуры данных является одной из самых распространённых задач.
Многие разработчики начинают работать с данными таблиц через числовые индексы, например row[2] или col[5]. Хотя такой подход позволяет быстро приступить к разработке, он приводит к серьёзной проблеме жёсткой привязки к строкам и столбцам. Код становится сложнее для чтения и поддержки, а любое изменение структуры таблицы — например, перестановка, добавление или удаление столбцов — может нарушить работу значительной части приложения.
В этой статье мы воспользуемся библиотекой Free Spire.XLS for Python, чтобы показать трёхэтапную эволюцию моделирования данных Excel:
Необработанные двумерные списки
Списки словарей
Списки пользовательских бизнес-объектов
Каждый подход подходит для определённых сценариев и уровней сложности. Отказавшись от жёстко заданных индексов, вы сможете сделать код обработки Excel более читаемым, поддерживаемым и масштабируемым.
Предварительные требования
Во всех примерах статьи используется пакет spire.xls, который позволяет читать, записывать, форматировать и пакетно обрабатывать файлы Excel без установки Microsoft Excel.
Подход 1. Хранение данных Excel в виде двумерного списка
Как это работает
Это самый простой способ чтения данных Excel. Мы последовательно перебираем используемый диапазон листа по строкам и ячейкам, сохраняя все данные в двумерный список, который полностью повторяет структуру исходной таблицы.
Полный пример
from spire.xls import Workbook
# Загружаем книгу и рабочий лист
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
# Получаем используемый диапазон
cell_range = sheet.AllocatedRange
# Сохраняем все данные в двумерный список
excel_data = []
for row_idx in range(cell_range.RowCount):
single_row = []
for col_idx in range(cell_range.ColumnCount):
# В Spire.XLS используются индексы, начинающиеся с 1
single_row.append(
cell_range[row_idx + 1, col_idx + 1].Value
)
excel_data.append(single_row)
# Освобождаем ресурсы
workbook.Dispose()
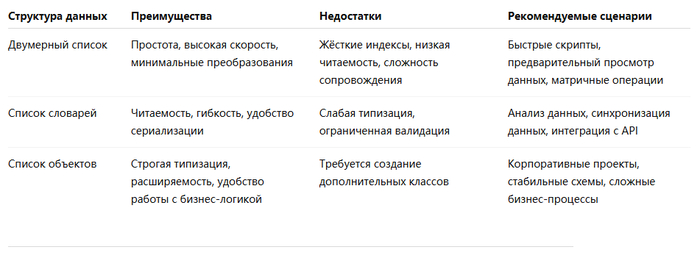
Преимущества и недостатки
Преимущества
Максимально простая реализация
Полностью сохраняет исходную структуру строк и столбцов
Не требует дополнительного преобразования данных
Недостатки
Доступ к данным осуществляется только через числовые индексы:
excel_data[row][col]
Такой код не несёт смысловой нагрузки. Если структура таблицы изменится, все ссылки на индексы придётся обновлять вручную, что усложняет поддержку и повышает риск ошибок.
Подходит для
Быстрых прототипов
Одноразовых скриптов
Матричных вычислений
Временного анализа данных
Для производственных приложений такая структура обычно не является оптимальным решением.
Подход 2. Преобразование строк в словари
Как это работает
Чтобы избавиться от жёстко заданных индексов столбцов, можно использовать первую строку как заголовки столбцов и преобразовать каждую последующую строку в словарь.
Вместо доступа к данным по позиции мы получаем доступ по имени поля. Это устраняет зависимость от порядка столбцов и значительно улучшает читаемость кода.
Полный пример
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
cell_range = sheet.AllocatedRange
# Извлекаем заголовки из первой строки
rows = list(cell_range.Rows)
headers = [
cell_range[1, col_idx + 1].Value
for col_idx in range(cell_range.ColumnCount)
]
# Формируем список словарей
data_list = []
for row in rows[1:]: # Пропускаем строку заголовков
row_dict = {}
for idx, cell in enumerate(row.Cells):
row_dict[headers[idx]] = cell.Value
data_list.append(row_dict)
workbook.Dispose()
Преимущества и недостатки
Преимущества
Теперь данные можно получать по понятным именам полей:
data_list[0]["Sales"]
Преимущества такого подхода:
Более высокая читаемость кода
Независимость от порядка столбцов
Простая сериализация в JSON
Удобная интеграция с API и конвейерами обработки данных
Хорошая совместимость с Pandas
Недостатки
Структуры на основе словарей по-прежнему являются слабо типизированными. Перед использованием данных может потребоваться дополнительная проверка и преобразование типов.
Подходит для
Импорта и экспорта данных
Очистки и подготовки данных
Генерации полезной нагрузки для API
Бизнес-отчётности
Универсальной обработки Excel
Для большинства приложений это оптимальный баланс между простотой и удобством сопровождения.
Подход 3. Сопоставление строк с пользовательскими бизнес-объектами
Как это работает
При работе с фиксированными схемами данных и более сложной бизнес-логикой словари могут оказаться недостаточно удобными. Они не обеспечивают типобезопасность, поддержку IntelliSense и не предоставляют естественного места для размещения бизнес-правил.
Более надёжный подход заключается в создании класса бизнес-сущности и преобразовании каждой строки Excel в экземпляр этого класса.
В результате получается строго типизированная модель, поддерживающая валидацию, бизнес-методы и более удобные инструменты разработки.
Полный пример
# Определение бизнес-сущности
class Employee:
def __init__(self, name: str, age: int | None, department: str):
Бизнес-правила могут быть реализованы непосредственно внутри сущности, а не распределены по всему приложению.
Подходит для
Корпоративных приложений
Стабильных и хорошо определённых схем данных
Систем со сложными бизнес-правилами
Долгосрочных проектов, требующих удобной поддержки
Как выбрать подходящую структуру
Оптимальный выбор зависит от сложности приложения и способа использования данных.
Заключение
Переход от:
Числовых индексов в двумерных списках
Семантического доступа через словари
Строго типизированных бизнес-объектов
отражает более широкий переход от ориентированного на данные программирования к моделированию, ориентированному на бизнес-логику.
Простые скрипты не требуют сложных абстракций. Для большинства реальных задач обработки Excel список словарей обеспечивает отличный баланс между гибкостью и удобством сопровождения. Если же приложение содержит сложные бизнес-правила и использует стабильные схемы данных, пользовательские объекты-сущности становятся наиболее надёжным долгосрочным решением.
Правильный выбор структуры данных позволяет значительно снизить сложность кода, повысить его читаемость, уменьшить количество ошибок и упростить сопровождение процессов обработки Excel по мере роста проекта.