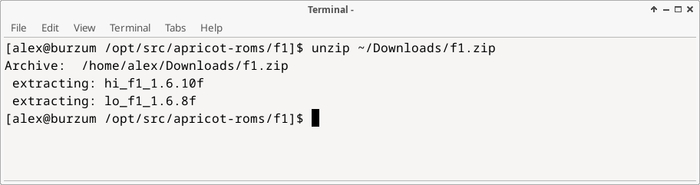
В Bash встроен синтаксис виртуальных путей вида /dev/tcp/host/port. Если попытаться открыть такой "файл" через редирект, Bash перехватит запрос и сам поднимет TCP-соединение.
В мире Kubernetes принято считать, что requests и limits - это надежные границы, которые полностью изолируют приложения. По факту же, когда память на ноде заканчивается, абстракции кубера отходят на второй план, и в игру вступают механизмы ядра Linux.
Решил разобраться в деталях и провел серию тестов в песочнице (ALT Linux 11, Minikube на Proxmox). Ниже - что из этого получилось.
Важно сразу разделить три разных сценария:
memcg OOM - контейнер упёрся в собственный memory limit.
kubelet eviction - kubelet заметил давление по ресурсам на ноде и начал выселять pod’ы.
global OOM - памяти на ноде не хватило быстрее, чем kubelet успел что-либо сделать, и сработал kernel OOM Killer.
Если смешать эти три механизма, легко случайно сделать неправильные выводы.
1. Лимит контейнера и cgroup v2: что происходит при memcg OOM
Самый частый сценарий: приложение внутри контейнера выходит за свой limits.memory.
В Kubernetes memory limit контейнера в итоге превращается в ограничение на уровне cgroup. В cgroup v2 жёсткий лимит задаётся через memory.max. Если потребление памяти в этой cgroup доходит до лимита и ядро не может освободить достаточно памяти, возникает memcg OOM.
На ALT Linux 11 используется cgroup v2 - как и в большинстве современных дистрибутивов Linux по умолчанию. Для Kubernetes это важный нюанс: в типовой конфигурации kubelet на cgroup v2 для container cgroup выставляется memory.oom.group=1.
Если там 1, то при OOM внутри конкретного контейнера ядро рассматривает процессы этого контейнера как единую группу и убивает их вместе. Это отличается от привычного поведения cgroup v1, где мог умереть один worker-процесс, а основной процесс контейнера продолжал жить, оставляя приложение в полуживом состоянии.
Но тут есть важная оговорка: для multi-container pod это не обязательно означает мгновенную смерть всех контейнеров pod’а.
Если OOM произошёл на уровне cgroup конкретного контейнера, будет убит именно этот контейнер. Если же давление по памяти возникло выше по иерархии cgroup или дошло до node/global OOM, поведение уже зависит от лимитов, QoS, oom_score_adj и того, кого ядро выберет жертвой.
Для диагностики полезно смотреть не только memory.max, но и memory.events:
Они помогают понять, что именно произошло: контейнер приблизился к лимиту, упёрся в memory.max, словил OOM или был убит группой.
2. А что насчёт memory.high?
В cgroup v2 есть не только memory.max, но и memory.high.
memory.max - это жёсткая граница. Если контейнер дошёл до неё и память нельзя освободить, будет OOM.
memory.high - это мягкий порог. При его превышении ядро начинает троттлить процессы в cgroup и заставляет их проходить через reclaim, то есть пытаться освобождать память до того, как ситуация дойдёт до убийства.
Звучит конечно красиво, но в Kubernetes есть нюанс: сам факт использования cgroup v2 ещё не означает, что memory.high реально настроен для ваших контейнеров.
Обычно memory limit контейнера мапится в memory.max. А вот активное использование memory.high связано с MemoryQoS и конкретной конфигурацией kubelet/runtime. Если MemoryQoS не включён или runtime не выставляет этот параметр, memory.high может оставаться равным max, то есть фактически не работать как предварительный тормоз перед OOM.
Проверять надо на живой ноде:
cat /sys/fs/cgroup/.../memory.high
Если там max, никакого троттлинга на этом уровне нет.
3. QoS-классы: кто на самом деле защищён?
Когда память заканчивается на всей ноде, важную роль играет oom_score_adj. Это поправка, которую Kubernetes выставляет процессам контейнеров, чтобы повлиять на выбор жертвы kernel OOM Killer’ом.
QoS-классы в Kubernetes такие:
Guaranteed
Pod получает Guaranteed, только если для каждого контейнера заданы и CPU, и memory request/limit, и при этом:
cpu request == cpu limit memory request == memory limit
Если забыли задать CPU request/limit - это уже не Guaranteed.
Для обычных пользовательских pod’ов это стандартный способ получить сильную защиту от OOM Killer’а:
cat /proc/$PID/oom_score_adj -997
BestEffort
Если у pod’а нет ни requests, ни limits, он получает BestEffort.
Такие процессы получают:
cat /proc/$PID/oom_score_adj 1000
Это первый кандидат на вылет при node/global OOM.
Burstable
Всё остальное - Burstable.
Для Burstable pod’ов oom_score_adj считается по формуле:
То есть чем больше memory request относительно памяти ноды, тем ниже oom_score_adj и тем меньше вероятность быть выбранным OOM Killer’ом.
В моей лабе это хорошо видно:
# Guaranteed pod
cat /proc/$(pgrep stress-ng)/oom_score_adj
-997
# BestEffort pod
cat /proc/$(pgrep alpine)/oom_score_adj
1000
Отдельный нюанс: системные процессы могут быть защищены ещё сильнее. В моей песочнице, например, kubelet имел oom_score_adj=-999, а sshd - -1000.
То есть Guaranteed - это не имба для пода. Это сильная защита по сравнению с обычными workload-процессами, но не абсолютная гарантия жизни.
4. QoS и eviction - не одно и то же
Тут легко ошибиться.
oom_score_adj важен для kernel OOM Killer’а, когда ядро уже само выбирает, кого убить.
А kubelet eviction работает иначе. Если kubelet успевает заметить memory pressure до global OOM, он выселяет pod’ы по своей логике. Там важны:
превышает ли pod свои requests;
PriorityClass;
насколько сильно usage превышает request.
QoS-класс коррелирует с этим поведением, но не является единственным алгоритмом eviction.
Например, pod с низким priority, но потреблением в пределах request, не обязательно будет выселен раньше pod’а с более высоким priority, который сильно вышел за request. Поэтому для анализа инцидента надо понимать, что именно произошло:
контейнер умер из-за своего memory limit;
pod был выселен kubelet’ом;
процесс был убит kernel OOM Killer’ом при global OOM.
Это разные события, и следы у них разные.
5. Global OOM: когда kubelet не успел
Если память на ноде закончилась резко, kubelet может не успеть сделать eviction. Тогда срабатывает обычный kernel OOM Killer.
Для проверки я запускал простой Python-скрипт, который агрессивно захватывал память:
import time
data = []
while True:
data.append(bytearray(100 * 1024 * 1024))
time.sleep(0.1)
В dmesg после этого можно увидеть что-то вроде:
Out of memory: Killed process 1841 (python3) total-vm:10GB, anon-rss:3.7GB, oom_score_adj:0
Здесь важно правильно читать поля.
total-vm - это виртуальное адресное пространство процесса.
anon-rss - реально резидентные анонимные страницы в RAM.
Разница между total-vm и anon-rss хорошо показывает, почему нельзя смотреть только на VIRT в top/ps и делать вывод, что процесс реально занял столько RAM. Но это ещё не вся история overcommit. Для анализа overcommit лучше смотреть глобальные счётчики:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Committed_AS показывает объём памяти, который ядро уже пообещало процессам.
CommitLimit показывает предел, после которого новые аллокации в strict mode должны начать отклоняться.
Ещё один важный момент при разборе OOM-логов: не путайте строки invoked oom-killer и Killed process.
Строка вида:
python3 invoked oom-killer
описывает процесс, который наткнулся на нехватку памяти.
А строка:
Out of memory: Killed process ...
описывает уже выбранную жертву.
Иногда это один и тот же процесс, иногда нет.
6. Опасные игры с vm.overcommit_memory
В Linux есть три режима overcommit:
0 — эвристика ядра
1 — always overcommit
2 — strict overcommit
В моей лабе на ALT Linux 11 после старта Minikube/kubelet значение vm.overcommit_memory переключалось в 1.
Проверяется так:
sysctl vm.overcommit_memory
Важно: это node-level sysctl, а не настройка конкретного pod’а или cgroup. Он влияет на поведение всей ноды.
Режим 1 разрешает агрессивный overcommit: процессы могут успешно получать виртуальную память «про запас», а реальные проблемы проявятся позже - когда память начнут фактически трогать и страницы станут резидентными.
Самая опасная ситуация - вручную переключить ноду в strict mode:
sysctl vm.overcommit_memory=2
В режиме 2 ядро начинает проверять, не превышают ли обещанные аллокации общий commit limit.
В моей лабе было 4 ГБ RAM, swap выключен, overcommit_ratio=50. Поэтому CommitLimit оказался около 2 ГБ:
sysctl vm.overcommit_memory=2
cat /proc/meminfo | grep CommitLimit
CommitLimit: 2005936 kB
Если нода уже нагружена и Committed_AS выше нового CommitLimit, такое переключение может быстро превратить систему в кирпич: новые процессы, fork, SSH-сессии и служебные демоны могут начать получать отказ на выделение памяти.
Перед включением strict mode надо хотя бы проверить:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Если Committed_AS уже выше будущего CommitLimit, включать strict mode нельзя без подготовки.
Более безопасный порядок такой:
sysctl vm.overcommit_ratio=80
sysctl vm.overcommit_memory=2
Но и это не рекомендация «делать в проде». Это настройка, которую надо тестировать под конкретный workload. Kubernetes-кластер с контейнерами, JVM, Python, Go-сервисами, базами данных и sidecar’ами может очень неприятно отреагировать на строгий overcommit.
7. Что реально помогают настроить kube-reserved, system-reserved и evictionHard
Чтобы нода не доходила до global OOM, Kubernetes даёт несколько механизмов резервирования.
kube-reserved - ресурсы для kubelet, container runtime и компонентов Kubernetes.
system-reserved - ресурсы для системных демонов ОС.
evictionHard - аварийный порог, при котором kubelet начинает выселять pod’ы.
Например:
kubeReserved:
memory: "512Mi"
systemReserved:
memory: "512Mi"
evictionHard:
memory.available: "500Mi"
Эти параметры не делают pod’ы магически безопасными. Они уменьшают Node Allocatable и создают буфер, чтобы kubelet успел начать eviction до того, как ядро сорвётся в global OOM.
Но если memory spike слишком резкий, kubelet всё равно может не успеть. Тогда решение будет принимать уже kernel OOM Killer.
Если контейнер умер из-за собственного лимита, обычно будет видно OOMKilled.
Если pod выселил kubelet, будет Evicted.
Если был global OOM на ноде, следы надо искать уже в dmesg/journal:
dmesg -T | grep -i -E 'out of memory|oom|killed process'
journalctl -k | grep -i -E 'out of memory|oom|killed process'
Итоги
requests и limits - это важные механизмы, но они не отменяют реальность Linux memory management.
Ключевые выводы всего вышеописанного:
Memory limit контейнера - это cgroup-лимит, а не предварительно зарезервированная RAM.
На cgroup v2 при memory.oom.group=1 процессы внутри контейнера обычно убиваются как группа. Но для multi-container pod это не всегда означает смерть всех контейнеров pod’а.
memory.high - полезный механизм cgroup v2, но не надо считать, что Kubernetes всегда его использует. Проверяйте реальное значение в cgroup.
QoS влияет на oom_score_adj, но kubelet eviction и kernel OOM Killer - разные механизмы.
Guaranteed - это сильная защита, но не гарантия бессмертия для пода. Системные процессы могут быть защищены сильнее, а при тяжёлом global OOM ядро всё равно будет кого-то убивать.
Strict overcommit mode опасен без расчёта Committed_AS и CommitLimit. Особенно на Kubernetes-нодах, где много процессов активно резервируют виртуальную память.
kube-reserved, system-reserved и evictionHard нужны не для красоты. Они дают kubelet шанс выселить pod’ы раньше, чем нода попадёт в global OOM.
Впрочем ладно, я зря драматизирую. AUR всегда был изрядной помойкой. Так что новость не удивительна (удивителен скорее масштаб).
Для тех кто всё еще не в курсе (хотя у арчеводов подгорает уже почти неделю). История следующая: Более 1500 пакетов в Arch User Repository оказались заражены малварью в результате скоординированной атаки на цепочку поставок.
Атака была обнаружена на прошлой неделе. Злоумышленники загрузили скомпрометированные PKGBUILD-файлы, которые при сборке пакетов выполняли вредоносный код. Arch-команда уже объявила, что инцидент взят под контроль. Но это не отменяет масштаба трагедии. Свыше 1500 пакетов - это определённо дофига.
Телеграм, ВКонтакте, Дзен, Макс — площадок становится все больше, а вот внимание аудитории по-прежнему ограничено. Что делать? Продвигать!
На Пикабу можно рекламировать свои каналы прямо в лентах сайта. Находите новую аудиторию и получайте живые переходы без сложных рекламных кабинетов.
Подойдет для:
авторских и экспертных блогов
бизнеса
медиа и новостных каналов
мемных и развлекательных сообществ
Запускается просто: добавляете ссылку, пишете заголовок и краткое описание и выбираете географию для показов. А дальше о вашем канале узнают тысячи пользователей Пикабу!
Помимо всем известной Apple, на свете существовала еще одна «фруктовая» компания, выпускавшая очень популярные компьютеры.
И сейчас мы цинично оживим и запустим эмулятор этих замечательных машин.
Главный герой все же справа а не слева.
Поскольку и сама компания и ее компьютеры и даже их эмулятор (вместе с его автором) — с берегов «туманного альбиона», большая часть ссылок в статье ведет в никуда на ресурсы, заблокированные для доступа из РФ, родной РКН к этому никакого отношения не имеет.
Поэтому надеваем монокли, цилиндры и поднимаем тост «За обход иностранных блокировок».
Изучая материалы из недавнего компьютерного прошлого, в который уж раз убеждаюсь:
за каждой успешной историей в ИТ есть натуральное кладбище из неудач и провалов.
А нынешние и всем известные «лидеры ИТ-индустрии» были отнюдь не первыми в своем деле и часто далеко не самыми инновационными. Еще у людей короткая память:
вчерашний «лидер рынка» и «король продаж» может легко и просто, а главное — невероятно быстро пропасть с концами из информационного поля.
Невзирая на всю шумиху в прессе, мощный пиар и даже народную любовь. Наша сегодняшняя история как раз про такую компанию:
Apricot Computers Ltd., originally Applied Computer Techniques Ltd. (ACT), was a British electronic company active from 1965 to 2005.
Who owned up to 30% market share in the UK, extended its sales in the USA and was ahead of IBM in the mid-80s in Europe?
Who was the first to launch speech recognition system for PC… in 1984?
Who introduced the first 3.5’’ floppy drive? The infrared trackball ? The keyboard with programmable functions keys along with a built-in LCD screen?
Who decided to deliver stylish designs, high resolution screens (800×400 in 1983), through a fully integrated conception in Scotland, allowing to manufacture in the early 90s one of the world’s most secure x86-based PCs?
Как видите, история получается более чем увлекательная, поскольку даже для весьма подкованного в винтажных вопросах автора эти факты оказались сюрпизом.
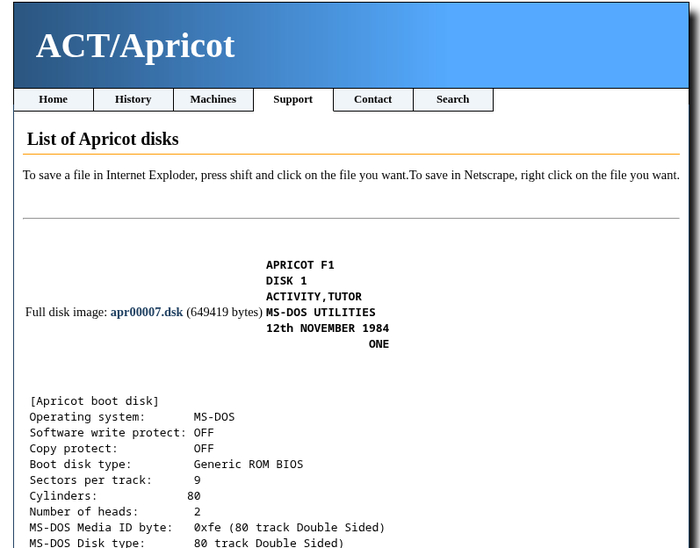
Так выглядел один из «абрикосов», предназначенный для корпоративного рынка:
Название к кириллице разумеется отношения не имеет — на экране отнюдь не буква «Ж», а стилизованное «Xi».
Поскольку был найден эмулятор этих интересных машин, решил попробовать это дело собрать и оживить. Однако все оказалось далеко не так просто и процесс написания этой статьи (вместе со сроками) пошел очень сильно не по плану, затянувшись на три месяца экзотических изысканий.
QDAE is a Quick and Dirty Apricot Emulator for Linux, Windows and MacOS X. This version emulates the Apricot F1, Xi and Portable; it may support other F-series and PC-series Apricots as well.
Основная разработка была закончена в далеком 2012 м году, собственно у файла Changelog, в котором находится описание изменений между версиями, дата последней модификации — май 2012 года. И с тех пор проект не развивается, можно сказать заброшен.
Сам эмулятор полностью оправдывает название «Quick & Dirty», поскольку был создан действительно «на коленке», на основе кодовой базы DOS-приложения а стабильность его работы — примерно как у Windows 95 оставляет желать лучшего.
Плюс документация (которой нет), ROM-файлы (которых тоже нет) и сами экзотические машины из далекого прошлого, физического доступа к которым нет и не предвидится.
Но разумеется все это меня не остановило.
Готовая сборка QDAE существует только для Windows, как оказалось в дальнейшем, автор эмулятора создавал эти сборки с помощью кросс-компиляции из-под Linux, причем очень старым компилятором.
Хотя все эти замечательные нюансы всплывут уже потом, скачивая первый раз сборку этого чуда, ни о чем подобном я и не подозревал.
Исходники находятся на личном сайте автора, никаких копий на GitHub обнаружено не было. Поэтому забирать придется оттуда:
Также архив с исходниками присутствует в Windows-версии эмулятора — будет лежать в каталоге установленного приложения. На всякий случай оставлю еще парулинков на сборки, поскольку непонятно как долго еще будет существовать личный сайт автора.
Образы ROM
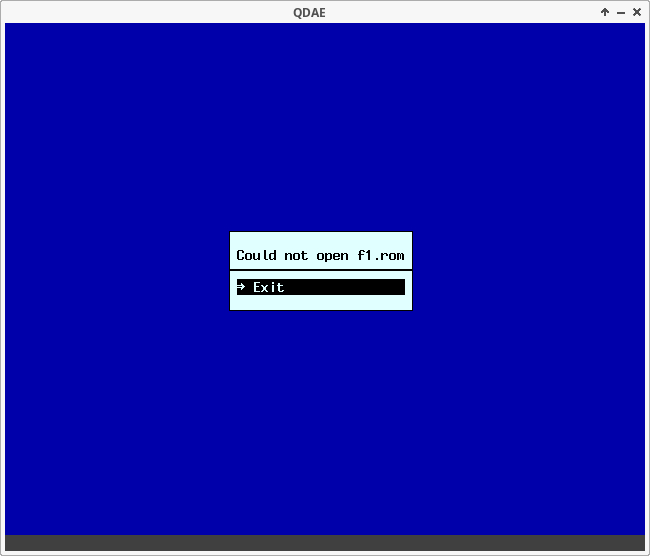
Первой проблемой с этим эмулятором оказалось полное отсутствие ROM-файлов, необходимых для работы. Сам автор с истинно британским юмором советует «снять дамп с работающей машины»:
For copyright reasons, QDAE is not supplied with any BIOS ROMs or disk images. Accordingly, when you launch QDAE for the first time, it will abort with the message: "Could not open f1.rom". You will need a dump of the F1 ROM (the F10 ROM is not suitable; the F2 ROM may work but has not been tested).
Если у вас есть возможность сгонять на выходные в Лондон, найти там одну из примерно таких сохранившихся машин:
И затем уломать владельца на проведение жестоких экспериментов с его музейным экспонатом — проблемы разумеется нет.
Но я был не в настроении путешествовать и подумал, что будет разумнее поискать эти самые ROM в сети.
простой народ в UK замучен копирайтерами до такой степени, что автор боится выложить загрузочный образ для компьютера из 1980х, произведенного компанией, которой давно не существует.
Представляете как надо было запугать людей? Зато обнаружился и легкий намек на то, как эти самые образы можно получить:
Дальнейшие изыскания показали, что образы вообщем-то в сети есть, причем ихдовольномного. Только с ними есть нюанс:
Файлов ROM оказалось два.
А эмулятору нужен один.
Что это вообще такое и как быть?
Не буду утруждать читателя всей историей изысканий, но мои поиски в итоге привели к этому gist:
Use this script to merge a pair of even+odd / low+high roms into a single file. You'll need to do this for games which have 16-bit CPUs which use 8-bit ROMs. Then, once you've merged each high/low pair, concatenate all the merged pairs into one single file to use in your disassembler.
Приведу код скрипта целиком:
#!/usr/bin/perl # # Merge a pair of hi/low byte roms into a single file # # Usage: merger.pl <low_or_even_byte_rom> <high_or_odd_byte_rom> >outputfile.bin open LO, $ARGV[0] || die $!; open HI, $ARGV[1] || die $!;
Еще на известном Archive.org выложена огромная коллекция образов (~90Гб!), среди которых присутствуют интересные образы дисков и для машин Apricot.
Запуск и работа
При попытке запуска версии для Windows, эмулятор откажется работать, выдав сообщение о том что ROM-файлы не найдены:
ROM-файлы читаются из каталога ~/.qdae/Roms, либо из %USERPROFILE%/Documents/QDAE в Windows.
Однако имена самих файлов зашиты в коде, например для машины «Apricot F1» файл называется f1.rom. Соответственно для того чтобы ROM-файл был найден и загружен эмулятором — недостаточно просто положить его в нужный каталог, нужно еще и соблюсти именование.
Напоминаю:
Без ROM-файлов эмулятор не заработает, совсем.
Как уже было отмечено выше, ROM-файл еще нужно собрать из двух частей, поскольку все доступные в интернете образы разделены на HI и LO части. В качестве примера, покажу весь процесс на ROM-файле для Apricot F1.
Как нетрудно догадаться по адресам сайтов, эти ROM были созданы для более известного и популярного эмулятора Mame, но мы ведь не ищем легких путей, правда?
В архиве будет два файла, которые необходимо соединить в один:
Копируем полученный ROM в домашний каталог с эмулятора:
cp f1.rom ~/.qdae/Roms/
Дальше можно пробовать запускать c использованием образа диска apr00007.dsk:
/opt/own/qdae/bin/qdae ~/Downloads/apr00007.dsk
Будет загружен MS-DOS 2.11 прямиком из 1984 года, так это выглядит:
Сборка
Если вы считаете себя нормальным или хотя-бы психически стабильным — просто скачайте готовую Windows-версию, благо она отлично устанавливается и затем запускается с помощью Wine.
Автор же заморачивался со сборкой и кровавым патчингом этого чудища только ради того чтобыповесить отрубленную башку над камином принципа и высоких достижений. Если вы простой обыватель — вам такие страдания и лишения точно не нужны. Теперь рассказываю как это было.
Получим каталог с набором трешевых исходников на C и C++ и скриптов сборки (autotools разумеется):
cd qdae-0.0.10 ./configure --prefix=/opt/own/qdae
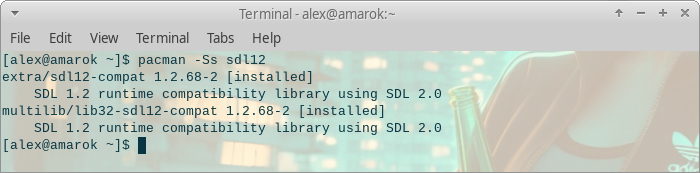
Сборка происходила на Linux Manjaro, ниже будут детали и особенности только по этому дистрибутиву. Эмулятор использует известную библиотеку SDL, причем первую версию, убедитесь что она установлена:
Как видите, я использовал даже не саму 1.х версию а слой совместимости для более современного SDL2
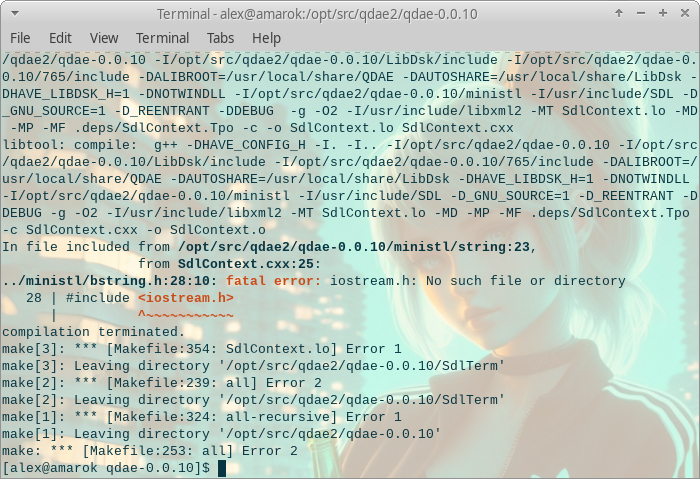
Запускаем сборку командой make и готовимся к первому «боссу». Первая ошибка, которая появляется при сборке на Linux выглядит так:
compress.c: In function ‘comp_open’: compress.c:137:37: error: implicit declaration of function ‘major’ [-Wimplicit-function-declaration] 137 | if (S_ISBLK(st.st_mode) && (major(st.st_rdev) == 2)) return DSK_ERR_NOTME;
Связана она с тем что функции major и minor объявлены устаревшими в заголовках текущей версии ядра Linux:
/* BSD defines `major', `minor', and `makedev' in this header. However, these symbols are likely to collide with user code, so we are going to stop defining them here in an upcoming release. Code that needs these macros should include <sys/sysmacros.h> directly. Code that does not need these macros should #undef them after including this header. */ # define __SYSMACROS_DEPRECATED_INCLUSION # include <sys/sysmacros.h> # undef __SYSMACROS_DEPRECATED_INCLUSION
Для исправления, необходимо добавить использование заголовка sys/sysmacros.h в начало файла LibDsk/lib/compress.c и перезапустить сборку.
Следующая ошибка, также связанная с этой проблемой выглядит так:
drvlinux.c: In function ‘linux_open’: drvlinux.c:182:13: error: implicit declaration of function ‘major’ [-Wimplicit-function-declaration] 182 | if (major(st.st_rdev) != 2) return DSK_ERR_NOTME;
Исправление аналогично предыдущей ошибке — просто добавляем эти строки в начало файла LibDsk/lib/drvlinux.c:
#include <sys/sysmacros.h>
После перезапуска сборки, появится куча ошибок вида:
f1_keyboard.cxx:57:32: error: invalid use of incomplete type ‘struct tm’ 57 | pkt[ 3] = 0x403 | ((ptm->tm_hour % 10) << 4); | ^~
Связаны эти ошибки с изменением структуры заголовков, конкретно — с переносом описания структуры времени из sys/time.h в просто time.h.
Для исправления ситуации, необходимо добавить включение этого заголовка в файле bin/sysdep.h:
#include <time.h>
После исправлений, сборка наконец завершается успешно. Однако собранный эмулятор откажется запускаться из каталога сборки:
Поэтому необходимо выполнить установку:
make install
В каталоге /opt/own/qdae появится сборка эмулятора, бинарник будет находиться в каталоге /opt/own/qdae/bin.
И уже отсюда собранный эмулятор можно наконец запустить.
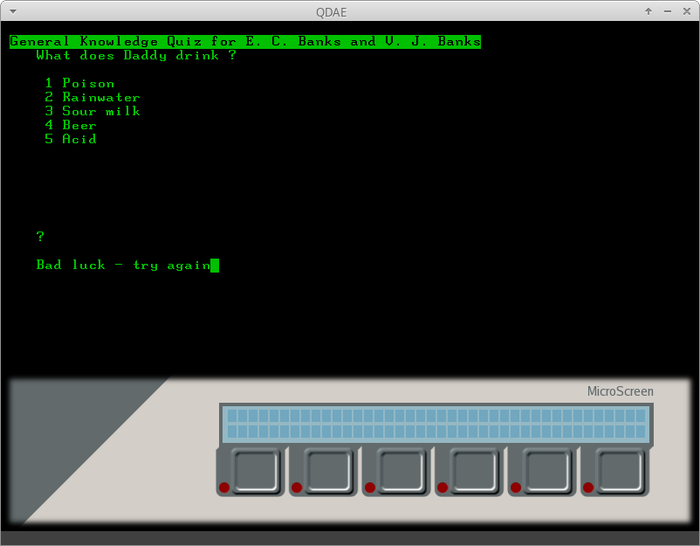
Так выглядит успешный запуск эмулятора с правильным ROM-файлом, но без каких-либо загрузочных дисков:
Мигающие индикаторы фиска и флоппи - как раз легкий намек на отсутствующий загрузочный диск.
Казалось бы все и вот она — победа, достойный результат многомесячного превозмогания, гугления и заморочек с ROM-файлами.
Увы но нет, дела с этим эмулятором обстояли куда сложнее, чем казалось изначально.
Внимание на экран:
На этом интересном месте происходит зависание эмулятора, отладчика и эмулируемой ОС — проще говоря:
наступает полный и тотальный.. конец всему.
Полный Пэ
Перед вами баг в эмуляторе компьютеров из 1980х от компании, которой больше не существует. Доживших до наших дней, действующих компьютеров Apricot осталось крайне мало, ближайший находится где-то в Лондоне.
Сам эмулятор написан 20 лет назад, с использованием ископаемых технологий тех лет, активная разработка давно прекращена, сайт заброшен а сам автор не отвечает.
Чтобы просто запустить эту йобу, пришлось потратить месяц на поиск и сборку ROM-файлов. Более-менее работает лишь Windows-версия, собранная последний раз в 2012м году.
Для Windows 7.
Мануалов фактически нет, исходный код внутри такой, что одним своим видом может напугать неподготовленного человека.
Даже без знания C/C++.
Ну что, взялись бы за работу по исправлению при таких-то вводных?
Письмо автору
На всякий случай сообщаю, что я не окончательно поехавший (несмотря на все статьи), поэтому первым делом честно попытался написать автору эмулятора:
Greetings Mr. Elliott.
I'm trying to resurrect the QDAE emulator and found a problem that I cannot solve.
I was able to fix the build process on Linux, found and successfully merged ROM files, found working disk images. But when emulator loads any graphical environment (ex. Activity) — emulated OS crashes or reboots.
Same problem persist with all types of emulated machines: right after it goes into graphics mode — emulated OS reboots or crashes.
I’ve tried to use this «server version» of MS DOS, found some disk images without automatic start for graphics. That worked and was more-less stable. But without graphics. Not fun.
Then tried to reduce speed ticks (in source code) — down to 1000, 500 or even 100 — emulation has became much slower, but issue not gone.
Tried to use fake year (1985) instead of calculated from the current timestamp — also didn’t help.
I’m not asking for exact solution, just point to right direction, because issues like that always come from something small or stupid.
There were some minor fixes I did, related to missing headers (due to changes in Linux kernel sources) with date-time functions, but don't think that it could be responsible for described issue.
Как видите, прежде чем писать письмо, было перепробовано много разных вариантов исправления ситуации для такого рода проблем, но ни один не сработал.
Дорога приключений
Собственно при таких раскладах оставалось только два пути:
потратить пару лет жизни (опять) на ковыряние кривых исходников на древнем C++, либо попытаться восстановить сборку Windows-версии, поскольку та по какой-то причине продолжала работать.
Для завершения этой статьи я выбрал второй путь. Так выглядит установка Windows-версии QDAE в Wine:
Кстати на ролике выше используется новый 10й Wine, с режимом WOW64 — т.е одна и та же версия может запускать как 32 так и 64-битные приложения, без всяких отдельных префиксов:
Так выглядит запуск Windows-версии эмулятора в Wine:
ROM-файлы необходимо скопировать в каталог .wine/drive_c/Program\ Files\ \(x86\)/QDAE/Lib/Roms/ :
Изучение
Я решил применить свои «особые навыки» и залезть внутрь Windows-версии эмулятора, использовав PE Explorer, который оказывается весьма неплохо работает под Wine:
Ковыряем один эмулятор с помощью инструментов, запущенных в другом эмуляторе.
Конечно я догадывался, что шансов встретить серьезную защиту в таком ПО не очень много, поэтому не заняло много времени выяснить ряд важных деталей:
сборка Windows-версии осуществлялась кросс-компиляцией из Linux, с помощью MinGW окружения;
использовалась 32-битная версия компилятора и соответственно получился 32-битный бинарник;
использовалась отдельная библиотека ministl (набор заголовков), вместо обычного STL — см. ниже.
Версия MinGW, используемого автором для сборки эмулятора оказалась невероятно древней:
GCC-2.95.2 for Mingw (i386-mingw32) -- Release information =================================================================== Release date: Nov 7, 1999. I'm pleased to announce prebuilt gcc-2.95.2 packages for GNU Mingw (i386-mingw32).
1999 год!
И вот этой ископаемой штукой, автор QDAE делал сборки своего эмулятора аж до 2012 года, причем из-под Linux.
Но это еще не все.
История с ministl
В каждой профессии обязательно есть вещи, о которых не принято говорить в приличном обществе. Обычно это знание спрятано за семью замками и железной дверью, в самом темном углу, дорогу к которому вам так просто не расскажут.
В случае программирования на C++ такой вещью является кастомный STL — «левая» реализация (от Васяна) стандартной библиотеки шаблонов «в переводе Гоблина».
Это самый темный угол C++, кладезь бесконечных и самых феерических багов, король дичи и программного треша, которые только можно сотворить в этом замечательном языке.
О самой возможности замены STL вам врядли расскажут вменяемые программисты, поэтому пишу отдельную статью по этой замечательной теме.
Думаю вы уже догадались, что автор QDAE как раз из таких использовал кастомный ministl при создании сборок своего эмулятора:
Тут должно быть драматическое молчание и МХАТовская пауза — для осознания.
Чиним сборку с ministl
Коль уж мы идем по пути восстановления сборки — придется пытаться собрать эмулятор с этим недоразумением вместо нормального STL.
Для этого необходимо запустить скрипт configure с указанием специального параметра:
./configure --with-ministl
И заново запустить сборку:
make clean make
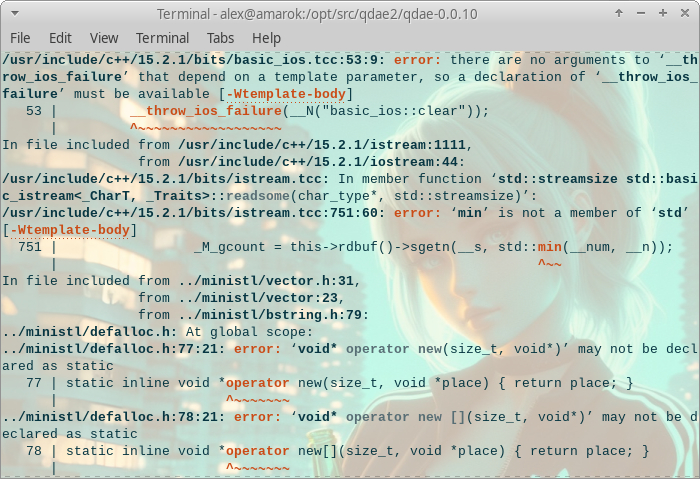
Разумеется сборка немедленно упадет:
Вы правда думали, что код на C++ из 1996 года соберется в современном окружении?
Хотя конкретно эта ошибка исправляется легко и просто — достаточно заменить устаревший заголовок <iostream.h> на просто <iostream>:
#include <iostream>
Сохраняем изменения в файле ministl/bstring.h и перезапускаем сборку. Но вот дальше.. дальше начинается ад и вьетнамские джунгли:
Хотя за исправление такого треша мне и платят.
Вас ожидает простыня ошибок из самых разных интересных мест, общий смысл которых:
иди своей дорогой сталкер, тебе тут не рады
Как понять, что вас ждут ад и погибель удивительные приключения и сутки тяжелой отладки?Копирайт с датами начала 90х в заголовке исходника на C++:
Copyright (c) 1994-1995 Modena Software Inc.,
Стоит рассказать потомкам, откуда вообще взялся этот bstring.h, вот так выглядит его оргинал из 1996 года. Все дело в том, что на свете есть одна известная и очень старая книжка по C++, которая называется:
STL Tutorial and Reference Guide:C++ Programming with the Standard Template Library
Книга, повторюсь, известная (даже я о ней слышал), думаю кое-кто из читателей держал такую на полке в свое время:
В комплекте с книгой шли примеры исходного кода на C++, одним из которых как раз и был наш bstring.h. Но это все лирика, реалии к сожалению таковы, что сил моих на исправление и переделку под современный C++17 этого древнего шаблона уже не хватило.
Точнее хватить-то хватило (на bstring.h), но обновленная версия ministl сломала весь остальной проект эмулятора, с концами.
Поэтому я его просто.. удалил.
Да, это еще одно тайное знание о заменяемом STL — возможность замещения системных шаблонов по частям.
На самом деле удалить нужно лишь файл string, из которого уже включается bstring.h:
rm ministl/string
Точно также я поступил и с vector.h, где вылезла следующая ошибка на тему новых стандартов и ограничений:
error: ‘void* operator new(size_t, void*)’ may not be declared as static
Объяснить с
Затем с list.h и ошибкой:
h6301.hxx:71:14: error: ‘list’ in namespace ‘std’ does not name a template type 71 | std::list<unsigned char> m_input; | ^~~~
Наконец последняя ошибка, связанная с ministl:
Path.cxx:199:9: error: ‘sort’ was not declared in this scope; did you mean ‘short’? 199 | sort(v.begin(), v.end()); | ^~~~
«Исправил» ее я аналогичным образом — цинично удалив заголовок ministl/algorithm.
Разумеется так делать нельзя и в нормальном проекте за подобные выкрутасы вас скорее всего побьют, возможно даже ногами.
Но и использовать «васянские» STL вместо стандартных — экстрим еще тот.
Со всеми этими правками, костылями и патчами сборка эмулятора наконец успешно завершается.
(бурные аплодисменты)
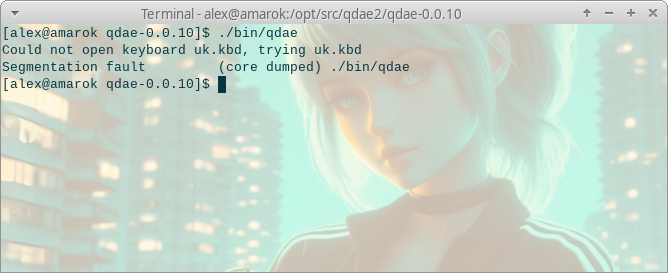
Но только собранный эмулятор все также не работает, зависая ровно на том же самом месте.
З2 веселых бита
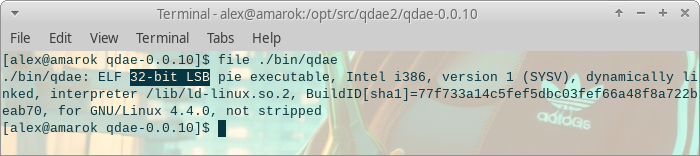
Как мы уже успели выяснить выше, работающая сборка эмулятора под Windows — 32-битная и была создана 32-битным компилятором, поэтому следующий логичный шаг это попытка сборки 32-битной версии.
И скажу сразу:
в современной системе такая сборка — то еще скотство
Нужно будет установить gcc multilib и 32-битные версии библиотек: SDL и всех остальных используемых библиотек, например libxml2. И все зависимости.
Так выглядит набор параметров, передаваемых скрипту configure для сборки и линковки 32-битного приложения в 64-битном окружении:
Давно хотел настроить вход и sudo по отпечатку пальца, но, как известно, в линях это проблема - поддерживается небольшое количество сканеров. Большинство того, что есть на рынке - не поддерживается из коробки. На предыдущем ноуте был встроенный сканер, в винде он отлично работал, в линях - нет. В этом ноуте встроенного сканера нет, покупал USB. Ссылку на него оставлю в комментах.
Я попросил ИИ-шку помочь с настройкой, и вот что получилось:
Сразу предупреждаю - действий много нужно сделать - 22 листа инструкция
Важное замечание: я сам по инструкции не делал, делал все ИИ-агент подключившись по SSH к моему ноуту, так что рекомендую протестить на виртуалке сначала. Агент тоже сначала тестил на виртуалке (сканер замечательно пробросился и заработал).
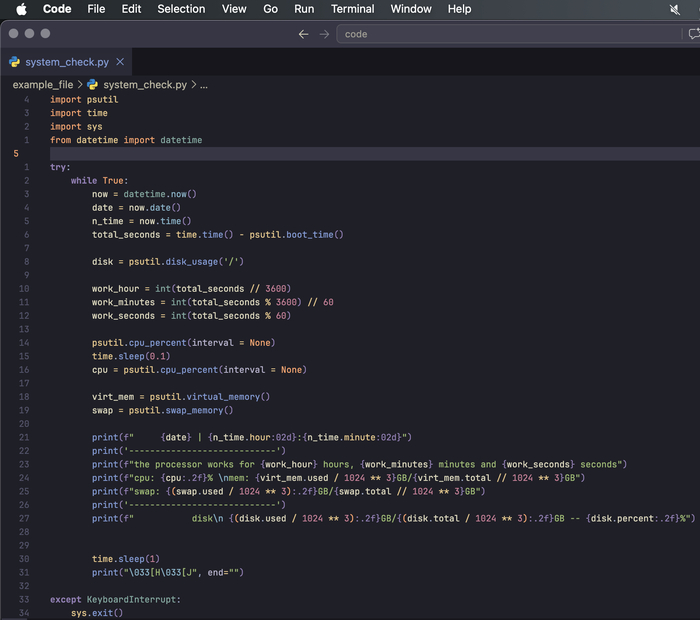
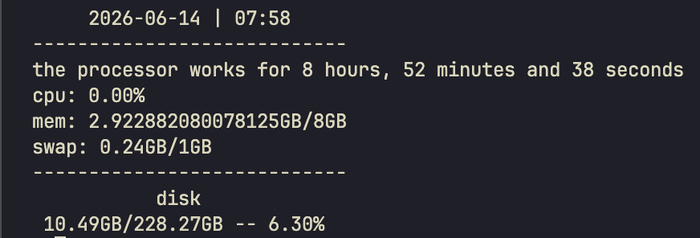
Был серьёзный перерыв, потеря мотивации и всё такое, с момента последнего поста углубился в работу с консолью, поставил две виртуалки дебиан, одну кде, другую hyprland, обе снёс из за того что надоел весь этот сахар, сегодня более или мненее разобрался с psutils, написал что то типа мини утилиты для бекапа системы, не на что не претендую, писал не для использования а для освежения навыков и изучения библиотеки, вот код и вывод:
В ИТ-индустрии существуют вещи, само существование которых давно стало красивым мифом, о котором принято вспоминать лишь шепотом и закатывая глаза от благоговения.
Настоящий Cray.
Cray
На сегодняшний день, во всем мире осталось наверное не больше пары сотен инженеров, заставших «те времена» и имевших возможность прикоснуться к легенде.
Лишь единицы из них еще могут что-то рассказать.
То что описано в этой статье — редчайшее знание, которое совсем недавно было доступно горстке избранных, с ученой степенью, специальной подготовкой и допусками к такому оборудованию.
Огромное, древнее чудовище из далекого прошлого, из времен мифов и легенд ожило и вернулось к жизни.. руками фанатов.
Дав возможность и простым людям прикоснуться к легенде.
Seymour Cray на фоне собственного суперкомпьютера.
Легенда
Персона Сеймура Крэя навсегда останется в анналах истории компьютеров, поскольку созданные его руками машины неоднократно признавались самыми быстрыми на планете.
Создаваемые полностью вручную (некоторые модели — вплоть до чипов) и имевшие цену в десятки миллионов долларов, суперкомпьютеры Cray поставлялись в исследовательские лаборатории, крупные датацентры и конечно же в разведывательные управления разных стран.
Про последнее стоит рассказать подробнее:
суперкопьютеры Cray всю историю плотно ассоциировались именно с секретными проектами, поскольку действительно часто использовались для взлома секретных кодов, паролей и шифров.
Что характерно, сам Крэй начинал карьеру во флоте (US NAVY) и работал над взломом японских шифров времен второй мировой войны, по всей видимости сохранив с тех лет хорошие отношения с главным разведывательным управлением.
У вас же, дорогой читатель шанс увидеть суперкомпьютер Cray был лишь в кино, где они довольно часто мелькали в качестве реквизита:
Ни о работе с такими машинами, ни тем более о разработке под них простым обывателям не стоило даже мечтать, даже если они родились и выросли в США. Допуски, специальное обучение с сертификацией и чаще всего наличие PhD — вот что обычно требовалось от «пользователей» подобного оборудования.
В Россию суперкомпьютеры Cray предсказуемо завозились с очень большими препонами и исключительно простые модели. В частности в Росгидромете была практика использования таких машин, начавшаяся еще в 90е.
Как бы то ни было, простому обывателю доступ к суперкомпьютерам Cray был заказан.
Я сам, несмотря на двадцать лет практики в разработке ПО, о них лишь слышал краем уха, да видел пару картинок в сети, вроде такой:
Производство суперкомпьютеров Cray-1
Тем удивительней оказывается история, рассказанная ниже.
Так выглядел случайно найденный бекап от суперкомпьютера.
Симулятор
История создания симулятора Cray за авторством Andras Tantos сама по себе достойна голливудской экранизации, поскольку являет собой победу инженерного духа над всеми преградами и трудностями:
So it’s settled. I’m building a Cray-1.
Крайне рекомендую ознакомиться со всей этой историей, поскольку по накалу повествования описываемые события сильно напоминают историю изучения египетского письма или попытки расшифровать немецкие шифры времен второй мировой.
Для примера, чтобы только прочитать данные со случайно обнаруженной ленты, автору пришлось реализовывать специальный драйвер для виртуального контроллера, полагаясь на такие картинки:
Затем пришлось вручную восстанавливать последовательность загрузки:
Разбираться с багами загрузчика и эмуляцией сети — не забываем что речь идет про суперкомпьютер, все основные части которого были связаны между собой по сети.
Andras провел чудовищную по объему и сложности работу, в успех которой к тому же никто особо не верил.
Именно поэтому результат его трудов настолько впечатляет.
Фронтальная панель суперкомпьютера Cray и индикаторы стадий запуска. Сверху кнопка включения.
Оживляем легенду
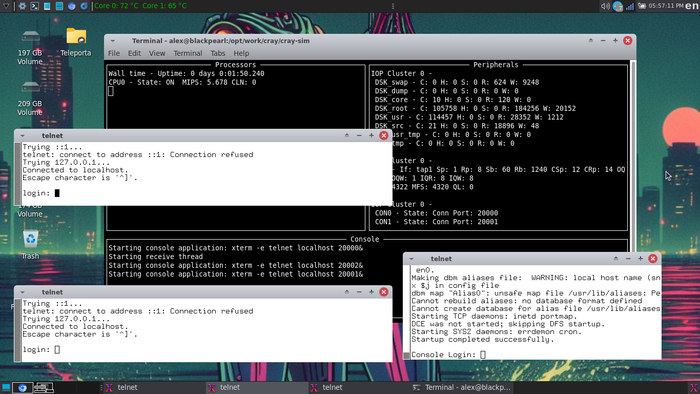
Симулятор использует внешние приложения для работы: xterm, telnet, tmux
Все это необходимо установить на хосте до первого запуска симулятора.
Дополнительно я использовал cool-retro-term для наведения красоты, чтобы снимки экрана выглядели еще эпичнее.
Важное уточнение:
несмотря на использование сетевого telnet, полноценное взаимодействие с запущенной UNICOS придется настраивать позже и отдельно — запускаемый при старте telnet-клиент на самом деле подключается к портам симулятора, через которые происходит трансляция консольных команд в виртуальную ОС и обратно.
Настоящее сетевое подключение к UNICOS требует специальной настройки на хосте, а поскольку инсталляция происходит по сети — сей шаг является обязательным.
Настройка выглядит следующим образом:
brctl addbr craybr ip tuntap add mode tap tap1 ifconfig tap1 up brctl addif craybr tap1 ifconfig craybr 172.16.0.1 netmask 255.255.255.0
Несмотря на всю внешнюю монструозность, ничего сложного тут нет:
создается новый мост с именем craybr, затем создается виртуальный сетевой интерфейс tap1, которому назначается IP-адрес 172.16.0.1.
Последним шагом этот интерфейс добавляется в мост.
Название интерфейса указывается в конфигурационном файле симулятора, который называется unicos.cfg, выдержка:
.. EthInterfaces {
en0 {
InterfaceNameLinux tap1
InterfaceNameWindows "Cray Ethernet"
SimMacAddr 0x020143524159
Channel 020
IopNumber 0
}
}
..
IP-адрес должен быть именно 172.16.0.1, поскольку внутренний интерфейс в UNICOS указан как 172.16.0.2 и поменять его достаточно проблематично.
Можно зайти и немного дальше, включив роутинг наружу:
В случае Mageia исходящий интерфейс будет называться по-другому, что-то вроде wlp4s0.
На стороне UNICOS в симуляторе необходимо выполнить команду:
route add default 172.16.0.1
Ну и радоваться — ведь вы только что выпустили в сеть суперкомпьютер Cray, пусть и виртуальный:
Все что вы видите в консоли выше - оригинальный софт от Cray, для суперкомпьютеров Cray.
Готовая сборка
Существуют готовые сборки симулятора Cray для 64-битного Linux, c уже установленным UNICOS версий 10.0.0.2 и 10.0.1.2, созданные известным в узких кругах камрадом neozeed.
Проблема в том, что эти сборки на момент написания статьи успели устареть (от 2022 года) и не факт что заработают в вашей системе.
А планов по обновлению у их автора нет.
Запускается симулятор из этих сборок с помощью стартового скрипта:
./unicos
Не забудьте что перед запуском необходимо выполнить скрипт для настройки сети (см выше).
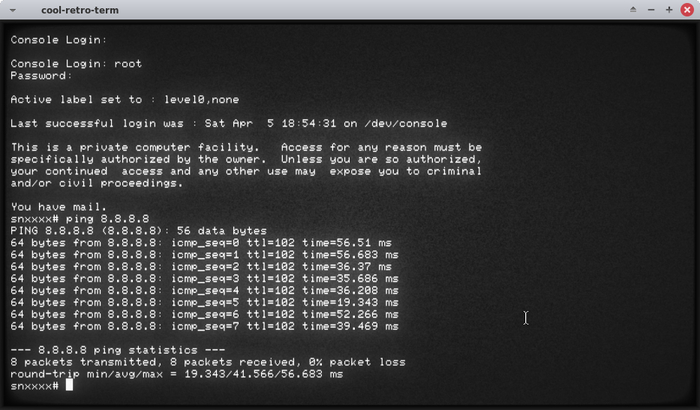
Так выглядит запуск UNICOS 10.0.1.2 в симуляции суперкомпьютера Cray J90:
Я заменил стандартный xterm, используемый симулятором по-умолчанию на cool-retro-term для большей эпичности скриншотов.
Но конечно у настоящего Cray J-90 не было настолько древних мигающих терминалов и все выглядело куда современне:
Если приглядеться, можно заметить на мониторе рабочей станции, характерные квадратные окна 4dwm — оконного менеджера SGI Irix.
Все потому, что в разные исторические периоды для суперкомпьютеров Cray использовались разные терминальные системы — SunOS, Irix и даже Mac:
Чтобы добиться такого же эффекта, измените поле настройки NewTerminalCommand в файле unicos.cfg:
Так выглядит UNICOS в запущенном состоянии:
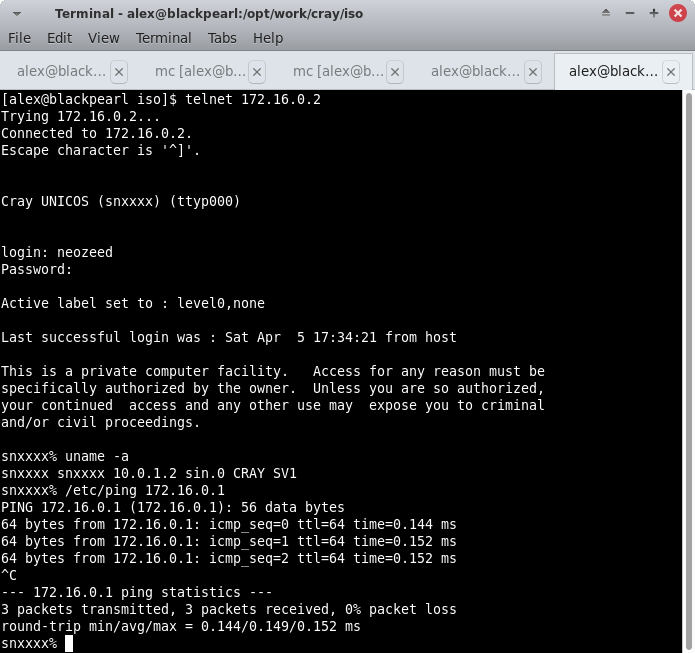
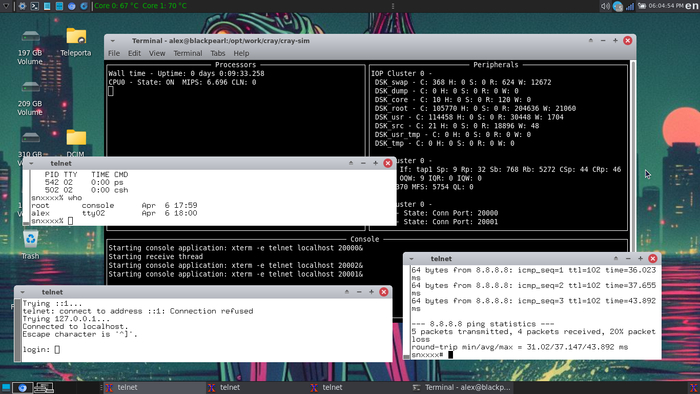
Согласно описанию автора, в системе есть следующие учетные записи:
The root password is 'password' and I've created a neozeed user with the password of 'password' so you can telnet in
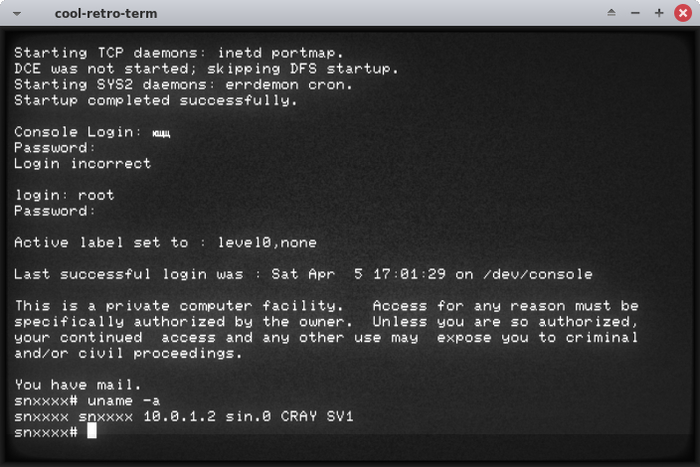
Входим от root:
Если вы все настроили правильно, также заработать сеть между симулятором и хостом, в обе стороны.
Появится возможность войти уже по сети, непосредственно на машину Cray:
Для завершения работы симулятора, введите команду exit в нижней консоли основного приложения и нажмите Enter:
То что нижний блок - тоже терминал, причем допускающий ввод, я догадался не сразу.
В принципе даже этой версии хватит для последующих развратных действий с участием компилятора (см. ниже).
Если у вас успешно заработала готовая сборка и нет настойчивого желания «собрать из исходников» — следущий шаг можно пропускать и переходить сразу к стадии действительно изысканных приключений.
Первые суперкомпьютеры Cray были обшиты натуральной кожей убитых инженеров.
Сборка из исходников
Несмотря на то что сие занятие — точно не для всех и любимый ChatGPT врядли подскажет что-то разумное по этому проекту, сделать все же стоит — для большего погружения.
Симулятор написан на C++, с использованием библиотеки Boost, поэтому компиляция из исходников протекает.. весьма неспешно.
Перед тем как запускать сборку необходимо установить следующие зависимости, версия для Ubuntu:
g++ make libboost-all-dev libncurses-dev libgpm-dev
Для Mageia:
gcc-c++ make lib64boost-devel lib64ncurses-devel lib64gpm-devel
Исходный код находится в каталоге simulator, поэтому сборка проекта также запускается именно оттуда, а не из корня репозитория.
Поскольку в пакетах Mageia нет статической версии библиотеки Boost, а для сборки Boost из исходниокв не хватило размеров статьи свободного места, я использовал динамическую линковку:
make LINK_TYPE=dynamic build
В Ubuntu сборка будет работать и вот так:
make build
Готовые бинарники будут находиться в каталоге simulator/_bin, но управляющие скрипты об этом знают, поэтому в ручную ничего перекладывать не надо.
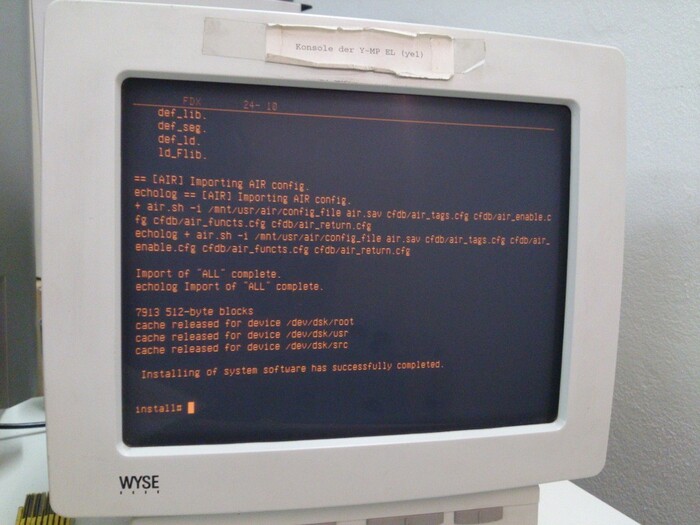
Завершение установки на одном из сохранившихся Cray Y-MP, консоль - реальный терминал Wyse тех лет.
Установка UNICOS
Теперь самая интересная стадия, которую вы пропустите если остановитесь на готовой сборке:
установка операционной системы UNICOS в симуляторе суперкомпьютера Cray из оригинальных образов CD-дисков.
Когда-то, за процесс ввода суперкомпьютера в эксплуатацию, отвечала целая команда высококлассных и сертифицированных инженеров, которые тщательно оберегали свои секреты.
Но благодаря любопытным фанатам, теперь наконец и вы сможете в этом поучаствовать.
Как уже описывал выше, два случайно обнаруженных диска оказались единственными сохранившимися носителями загрузочного образа UNICOS и без них судьба симулятора сложилась бы совершенно иначе.
Оба диска являются загрузочными, первый содержит UNICOS версии 10.0.0.2 для модели Cray J90, второй — UNICOS 10.0.1.2 для Cray SV1.
Шаги установки полностью совпадают, но устанавливать я буду более свежую версию 10.0.1.2, со второго ISO‑образа. Несмотря на то что разные версии этой ОС предназначены для установки на разные суперкомпьютеры, в условиях симулятора все отлично работает.
Так выглядит модель Cray SV1
Инструкция по установке от автора симулятора, находится тут, но к сожалению она успела немного устареть, поэтому придется использовать описанные в ней шаги с небольшими изменениями.
Напоминаю, что все команды ниже, выполняемые с хоста, как и управляющие скрипты симулятора подразумевают использование bash.
Со стороны UNICOS используется ksh, но для стадии установки это не особо важно.
Для упрощения вводимых команд, зададим две переменные окружения:
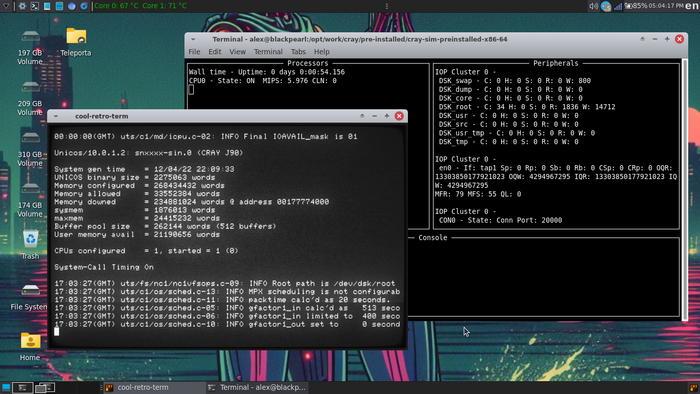
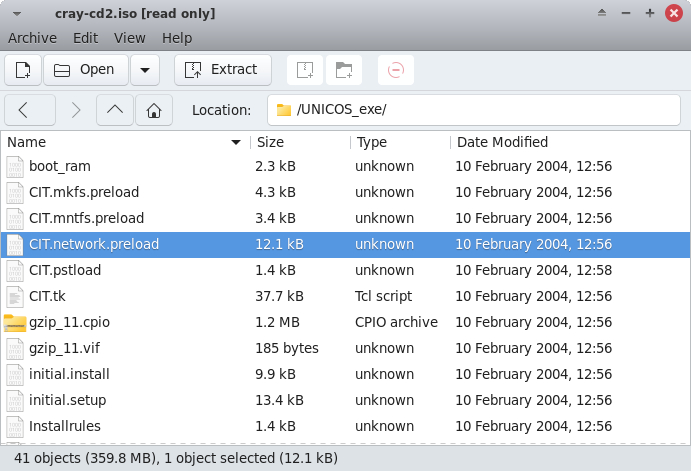
В корневом каталоге симулятора появятся несколько новых файлов, нужный нам называется unicos.generic — то самое ядро.
На этой стадии можно наконец запустить симулятор, но пока с использованием образа RAMFS, который мы только что скопировали с установочного диска:
./unicos_ramfs
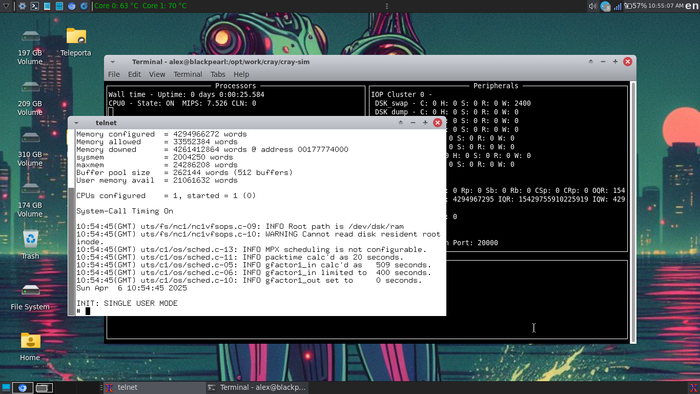
Запустится симулятор и появится терминал с подключением к UNICOS, запущенной в single user mode:
Кто бы мог подумать, что смогу запустить в Single User Mode ОС для суперкомпьютеров Cray!
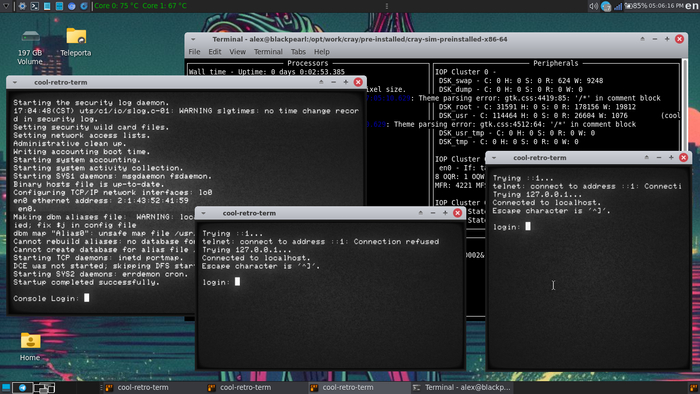
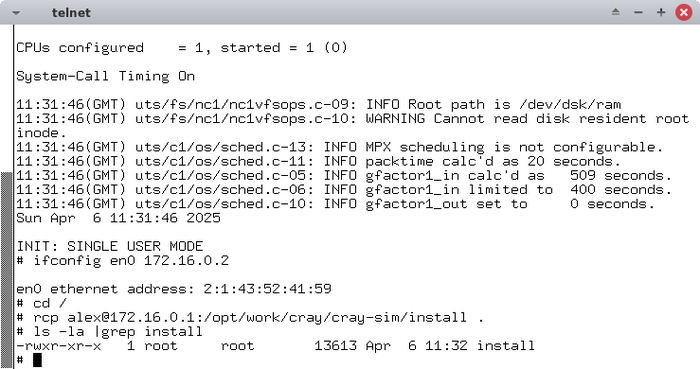
Теперь настраиваем сеть на стороне UNICOS, поскольку следующим шагом необходимо копировать системные файлы с примонтированного ISO-образа.
Напомню что подключение через telnet происходит на самом деле к самому симулятору, не к эмулируемой ОС внутри.
Вводим в консоли UNICOS:
ifconfig en0 172.16.0.2
После выполнения команды должна отрабатывать команда ping до хоста:
Дальше начинается еще один интересный этап, полный боли и страданий, поскольку придется встретиться с одной очень древней технологией передачи файлов между компьютерами — rcp.
UNICOS, который мы с вами запускаем это система из далекого 1997 года и ничего другого для передачи файлов в ее загрузочном образе просто нет.
Когда-то предполагалось, что весь процесс установки и запуска в эксплуатацию суперкомпьютера — строго секретный, поэтому с «usability» не заморачивались.
Есть еще один важный нюанс:
единственная доступная в образе утилита для передачи файлов на расстояние это клиент.
Для того чтобы подключиться с его помощью и скачать файл, надо поднимать сервер, сервер древнего rcp и на современном линуксе.
Ввиду своей древности, rcp в любом виде (как клиент и как демон) давно отсутствует по-умолчанию в любых линуксах и BSD, а его установка и запуск в современном окружении требует «особой уличной магии».
Для Ubuntu вам будет необходимо установить пакеты:
rsh-client rsh-server
Для Mageia:
rsh rsh-server
В последней запуск rsh-сервера происходит через демон xinetd, который по-умолчанию отключен и попытка запуска будет выдавать ошибку:
xinetd.service is not active, cannot reload.
Поэтому сначала запускается xinetd, затем rsh:
service xinetd start service rsh start
Следующим шагом необходимо разрешить использование демона rsh по сети (входящие подключения), для Ubuntu необходимо добавить строку в файл /etc/hosts.equiv:
172.16.0.2 +
Для Mageia используется файл ~/.rhosts.
Это позволит подключиться к хосту и скопировать стартовый скрипт инсталляции в запущенную UNICOS.
Но прежде чем копировать, скрипт необходимо немного изменить.
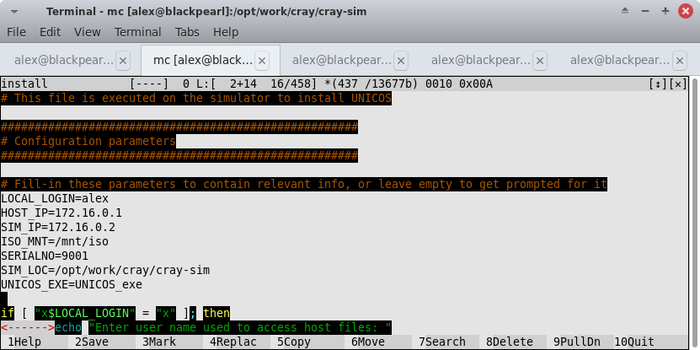
Открываем файл install (находится в корневом каталоге симулятора) любимым редактором vi и заполняем значения переменных:
LOCAL_LOGIN = имя пользователя на хосте
ISO_MNT = /полный/путь/к каталогу с образом UNICOS
Также добавляем новую переменную SIM_LOC, которой устанавливаем значение в виде полного пути к каталогу с симулятором.
Заранее предупреждаю, что в скрипте инсталляции есть небольшая ошибка, связанная с определением версии устанавливаемой системы. На процесс инсталляции она не влияет, но бесит и раздражает, поскольку появляется в самом начале.
Чтобы ее избежать, необходимо задать еще одну переменную:
UNICOS_EXE=UNICOS_exe
В результате всех описанных выше правок должно получиться такое:
Финальный скрипт установки операционной системы Cray, мама будет вами гордиться ;)
Cохраняем изменения, затем на стороне UNICOS вводим команды, заменив предварительно имя пользователя и путь к симулятору:
cd / rcp alex@172.16.0.1:/opt/work/cray/cray_sim/install .
В результате выполнения команды файл install будет скопирован с хоста и появится в корне файловой системы UNICOS:
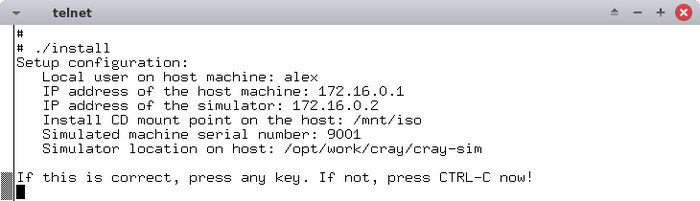
Появится сообщение с перечислением введенных параметров:
Нажимаем любую клавишу и запустится увлекательный процесс установки операционной системы для суперкомпьютера Cray:
Несмотря на эпичность, это всего лишь копирование файлов по сети.
Процесс достаточно длительный и занимает несколько часов, вне зависимости от мощи вашего оборудования, так что вполне успеете принести кровавую жертву темным богам выпить чаю в хорошей компании.
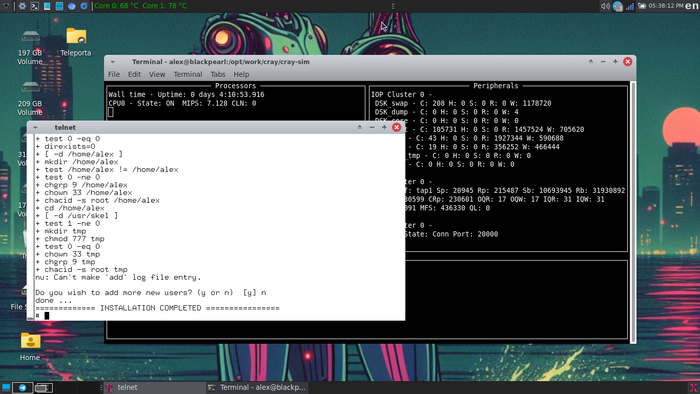
В самом конце установки, будет предложено установить пароль для суперпользователя, а также будет запущен диалог создания учетной записи обычного пользователя.
После чего установка наконец будет завершена:
Да, вы только что установили ОС на суперкомпьютер Cray, пусть и виртуальный.
Во время установки UNICOS происходит один очень важный шаг, о котором стоит рассказать — линковка ядра.
Эта практика происходит из времен первых UNIX, когда архитектур было много а стандартов мало. Совместимость оборудования хромала, поэтому такая линковка использовалась в качестве своеобразного финального теста системы.
Из современных операционных систем, эту практику сохранила например OpenBSD, хотя и по другой причине.
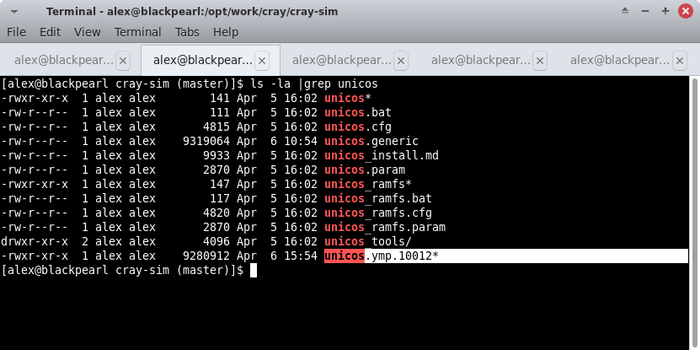
Останавливаем симулятор командой exit и убеждаемся, что основное ядро UNICOS успешно слинковано — должен появиться файл unicos.ymp.10012:
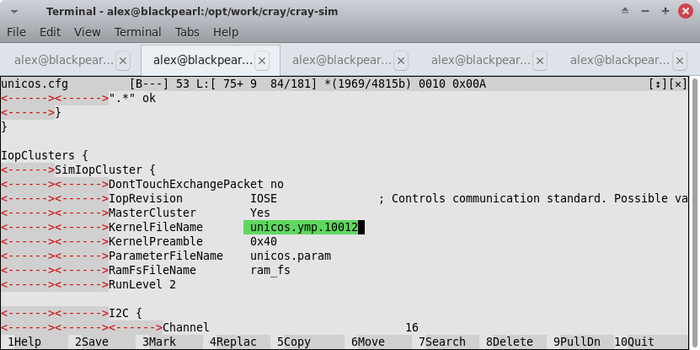
После этого, проверяем файл unicos.cfg, в котором должно появиться указание на новое ядро:
Если все хорошо и ссылка на свежее ядро на месте, запускаем полноценную симуляцию:
./unicos
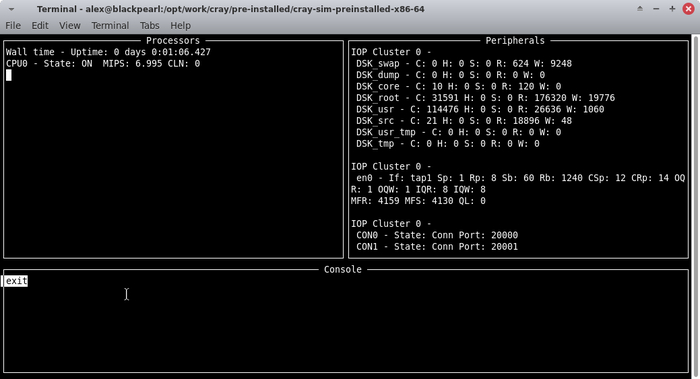
Так выглядит полностью запущенный симулятор суперкомпьютера Cray J90 с только что установленной UNICOS:
Если на стороне UNICOS прописать маршрут по-умолчанию, такой же командой как и в готовой сборке:
route add default 172.16.0.2
..получим выход в интернет.
Прямо с суперкомпьютера Cray, вы правильно поняли:
Мам, я вывел суперкомпьютер Cray в интернет!
Вы же не думали, будто на этом я успокоюсь, открою шампанское, вызову девок и уйду в загул? Конечно же нет и впереди ждет еще много интересного и удивительного.
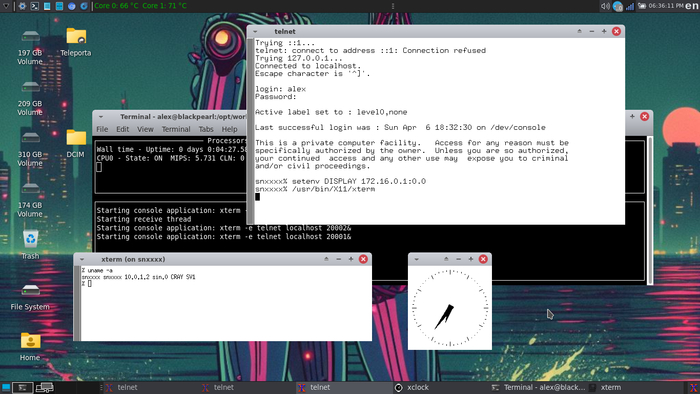
Графический интерфейс, на суперкомпьютере
В найденных образах UNICOS, один из которых мы только что использовали для установки, была обнаружена работающая клиентская библиотека для протокола X11.
Самого X-сервера внутри разумеется нет, поскольку далекие предки использовали специальные управляющие терминалы с SGI Irix:
Зато есть возможность пробросить отображение приложения с поддержкой протокола X11, чтобы оно отрисовывалось на запущенном современном Xorg-сервере хоста.
Что автор немедленно и проделал:
Часики, которые тикают прямо на суперкомпьютере Cray.
Два приложения на скриншоте выше xterm и xlock — запущены из работающей UNICOS и отображаются в Xorg-сервере на Mageia Linux.
Чтобы это повторить, необходимо принести кровавую жерт.. ээ выполнить три простых шага, описанные ниже.
Запуск Xorg-сервера с поддержкой сети
По-умолчанию и очень давно, даже в самых олдскульных дистрибьютивах вроде Slackware, X-сервер запускается с параметром -nolisten, запрещающим удаленное подключение по сети.
Чтобы в этом убедиться, достаточно выполнить команду на хосте, которая покажет запущенный X-сервер со всеми параметрами:
ps -ax |grep X
Запускается X-сервер из специального приложения «display manager» (dm), который ответчает за красивое графическое окно авторизации, поэтому параметры запуска X-сервера указываются в настройках этого менеджера.
Поскольку в моей системе используется LightDM, для того чтобы X-сервер начал прослушивать сетевой порт, я добавил следующую настройку в раздел [Seat:*] в файл /etc/lightdm/lightdm.conf.d/49-mageia.conf:
После чего сервис lightdm необходимо перезапустить:
service lightdm restart
Естественно вас в этот момент выбросит из системы, так что будьте готовы и остановите заранее симулятор, если он был запущен.
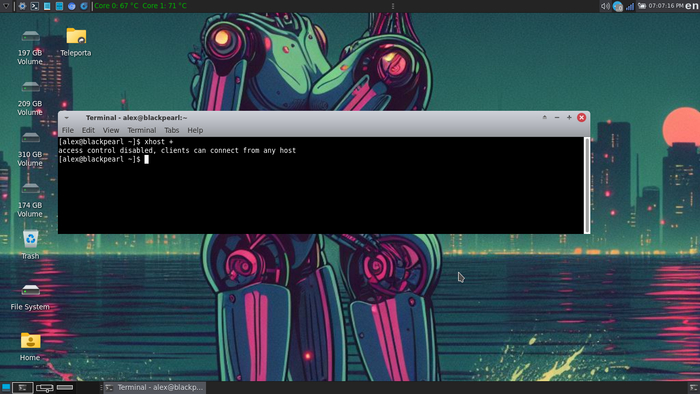
Разрешение удаленного доступа без авторизации
Следующим шагом необходимо отключить авторизацию при подключении к X-серверу по сети.
Для этого авторизуйтесь с помощью DM и запустите графическое окружение — как вы обычно это делаете, затем введите в консоли:
xhost +
Выглядит это так:
После выполнения этой команды будет доступно удаленное подключение к вашему X-cерверу с любого хоста.
Что конечно считалось опасным еще лет двадцать назад, но в нынешние продвинутые времена (с Wayland вместо Xorg), когда о самой возможности такого удаленного подключения уже мало кто помнит — не стоит заморачиваться:
все, кто теоретически смог бы таким образом подключиться к вашей машине давно умерли или наслаждаются маразмом.
Кроме автора, разумеется.
Указание адреса удаленного X-сервера
Наконец последним шагом необходимо указать адрес удаленного X-сервера на стороне UNICOS. Делается это командой (не забываем о ksh по-умолчанию):
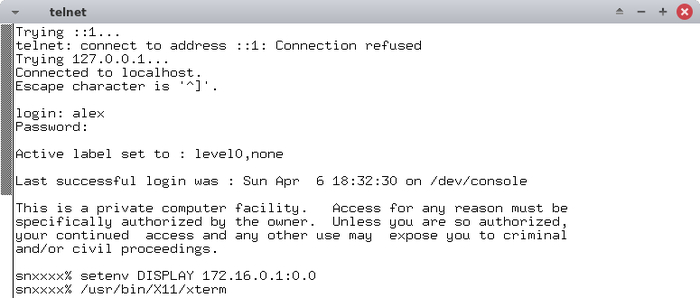
setenv DISPLAY 172.16.0.1:0.0
Набор софта с графическим интерфейсом находится в каталоге /usr/bin/X11, так для примера выглядит запуск xterm:
"This is a private computer facility" - самое возбуждающее приглашение на свете.
Если вы выполнили все шаги правильно, появится графическое окно, с запущенным приложением, работающим в среде суперкомпьютера:
И.. нет, это еще не конец.
Особенные радости, для особенных
Вместе с симулятором поставляется интересный архив goodies.tar, собранный оригинальным автором симулятора, который можно найти в каталоге unicos_tools.
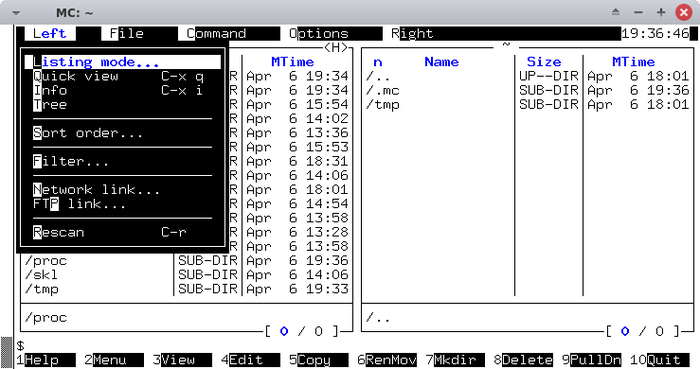
Архив содержит несколько известных утилит, собранных для UNICOS, без которых жизнь юниксоида сера и уныла — bash и midnight commander.
Узрите смертные, ибо так выглядит ваш любимый mc , запущенный на суперкомпьютере Cray:
Страшно? А мы предупреждали.
Копируется сей замечательный архив с помощью уже известного по процессу установки rcp:
Привет, Пикабу! Я отвечаю за ИТ и цифровую трансформацию (CDTO/CIO) на крупном промышленном предприятии. Если вы работаете в энтерпрайзе, то наверняка знаете эту боль: бизнес приходит и говорит «Хотим свой ChatGPT, чтобы он читал наши чертежи и оптимизировал производство!». А следом приходит служба информационной безопасности (ИБ) и молча кладет на стол регламенты.
В нашей реальности облачные LLM (будь то зарубежные или отечественные по API) мертвы по определению. Коммерческая тайна, строгая регуляторика, жестко изолированный контур (air-gapped сети) и гетерогенный парк на базе Astra Linux диктуют свои правила. Нам нужен локальный, полностью суверенный ИИ.
Важная оговорка: всё, о чем пойдет речь ниже — это результаты моего независимого исследования. Я собрал локальный стенд на собственном оборудовании, сфокусировавшись на типовых проблемах промышленности, но без использования служебных данных и корпоративной инфраструктуры. В этой статье я расскажу, как уйти от игрушечного «промт-инжиниринга» к распределенным мультиагентным системам, как математически обосновать закупку GPU-кластера и как заставить локальные модели работать быстро, не выжигая железо. Будет много технического мяса.
1. Иллюзия монолитных запросов и переход к мультиагентности
Если попытаться развернуть большую локальную модель (70B+) и «скормить» ей в контекст гигабайты нормативки, результат предсказуем: модель либо захлебывается (out of memory), либо начинает галлюцинировать, придумывая несуществующие пункты регламентов. Монолитные LLM хороши для генерации писем, но для сложных промышленных задач они непригодны.
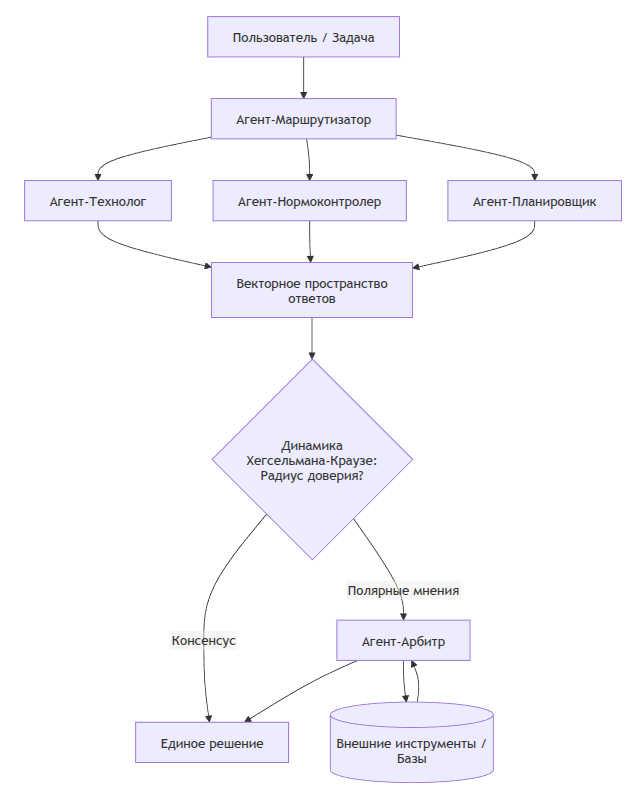
Я спроектировал архитектуру на основе мультиагентных систем (MAS). Вместо одного «всезнающего» ИИ работает рой небольших специализированных моделей (14B-32B).
Как заставить их договариваться?
Чтобы агенты (например, «Агент-Технолог», «Агент-Нормоконтролер» и «Агент-Планировщик») не спорили бесконечно, их координация формализуется как децентрализованный частично наблюдаемый марковский процесс принятия решений (Dec-POMDP). Каждый агент видит только свою часть производственной задачи, но максимизирует общую функцию полезности.
Для согласования ответов экспертных агентов я применил математический аппарат нелинейной динамики Хегсельмана-Краузе (Hegselmann-Krause). В классической модели Х-К мнения агентов сходятся, если они находятся в пределах «радиуса доверия». Для LLM это выглядит так: если эмбеддинги ответов агентов находятся близко в векторном пространстве, они сливаются в единое решение (консенсус); если мнения полярны — запускается арбитражный агент, который вызывает внешние инструменты проверки.
Пример из практики: мы используем открытые веса эффективных моделей семейства Qwen (например, Qwen 2.5 на 14B-32B параметров). При проверке легальности, нормативного соответствия или подборе сложных кодов (технологических или таможенных) один Агент-Эксперт генерирует гипотезу, а другой, Агент-Нормоконтролер, жестко сверяет ее по RAG-базе локальных ГОСТов. Динамика Х-К позволяет им достичь консенсуса, исключая галлюцинации: если первый придумывает несуществующий пункт, второй не принимает этот токен (их мнения полярны), и арбитр запрашивает перегенерацию с прямой выдержкой из PDF.
Безопасность и верификация графа
В промышленности цена ошибки ИИ — это остановка линии или брак партии. Поэтому необходим жесткий контроль пайплайнов с помощью раскрашенных сетей Петри (Colored Petri Nets, CPN).
CPN позволяет статически верифицировать граф исполнения агентов до его запуска. «Фишки» (токены) в сети несут в себе типизированные данные (json-объекты с контекстом), и мы математически гарантируем, что агент не сможет передать секретный чертеж агенту, у которого нет нужного уровня допуска (аналог мандатного доступа Astra Linux), а также то, что процесс не уйдет в бесконечный цикл (deadlock).
2. Выживание на одной RTX 3090: как впихнуть невпихуемое
Давайте без иллюзий. Когда мы говорим «ИИ для энтерпрайза», многие представляют себе стойки с H100. Но в реальности тестирование гипотез, RAG-конвейеров и парсинга нормативки (для моих pet-проектов) происходило у меня дома, на одной-единственной десктопной RTX 3090 с 24 ГБ VRAM.
В 24 ГБ VRAM физически не влезает неквантованная модель на 32B, не говоря уже про контекст в 100k-200k токенов (а приказы и ГОСТы, которые я загружал в прототипы, легко съедают этот объем). Оптимизация инференса здесь — вопрос выживания, а не красивых графиков.
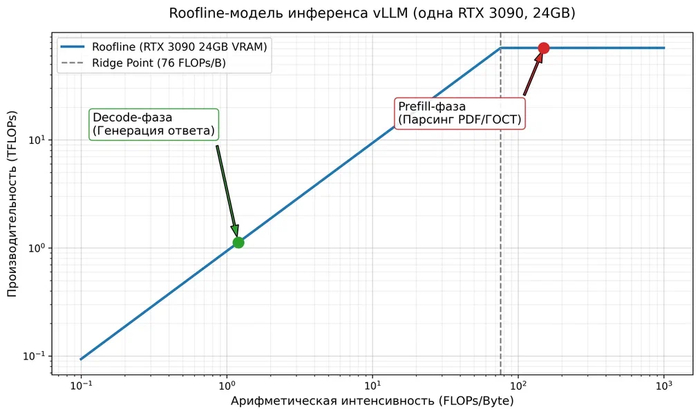
Я профилировал работу моделей через двухфазную модель Roofline:
Prefill-фаза (когда модель «проглатывает» промт с кучей документации): мы упираемся в вычислительную мощность (compute-bound).
Decode-фаза (когда модель отвечает): мы упираемся в пропускную способность памяти (memory bandwidth-bound).
Самой большой болью стал KV-кэш. При потоковой обработке документов в `vLLM` с окном контекста в 128k–262k токенов кэш мгновенно выедал всю оставшуюся видеопамять (OOM).
Мой стек оптимизации для RTX 3090:
Квантование: Я перешел с тяжелых весов на GGUF и AWQ (FP8). Это позволило уместить веса хорошей модели семейства Qwen в ~12-14 ГБ VRAM, оставив место под контекст.
Heavy Hitter Oracle (H2O): Для сжатия KV-кэша. В механизме внимания не все токены одинаково полезны. H2O динамически оценивает «важность» токенов в кэше и безжалостно отбрасывает (evict) лишние, оставляя только Heavy Hitters (токены, на которые опирается смысл) и небольшое окно свежих токенов.
Разделение нагрузок: В проектах я вынес генерацию векторов (эмбеддингов) и задачи OCR в ONNX-рантайм (только CPU/RAM), чтобы полностью отдать дефицитную видеопамять под `vLLM` сервер.
Именно эти суровые "домашние" ограничения научили меня делать по-настоящему эффективные локальные архитектуры, которые на заводах смогут работать не на суперкомпьютерах, а на обычных серверах с бытовыми или полупрофессиональными GPU.
3. FinOps: Как защитить бюджет на GPU-кластер
Финдиректору плевать на H2O и сети Петри. Ему нужны цифры. Инвестиции в локальные GPU — это тяжелый CapEx.
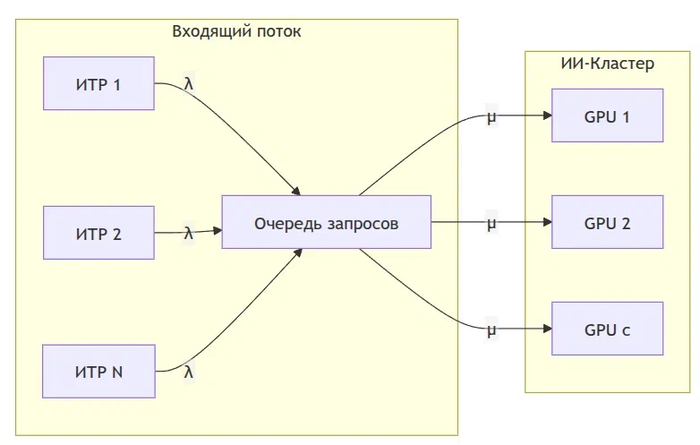
Чтобы обосновать размер кластера, я предлагаю использовать теорию массового обслуживания (СМО). Локальный API моделируется как система типа M/M/c, где:
пуассоновский входной поток заявок (λ) — это запросы от ИТР (инженерно-технических работников);
экспоненциальное время обслуживания (μ) — это время инференса;
c — количество параллельно работающих GPU/инстансов моделей.
Построив график вероятности ожидания в очереди P(W>0) в зависимости от количества видеокарт, можно найти точку экстремума, где добавление новых GPU уже не дает существенного прироста утилизации (закон убывающей отдачи). Это дает точное понимание, сколько железа брать в первую очередь, не переплачивая за простаивающие мощности.
Далее это упаковывается в финансовую модель:
Считается ROI (Return on Investment) и NPV (Net Present Value) проекта на горизонте 3 лет.
В графу доходов закладывается не мифическая «инновационность», а конкретные FTE (Full-Time Equivalent): сколько человеко-часов высокооплачиваемых инженеров высвобождается от рутинного поиска по документации и формирования отчетов.
Учитывается стоимость рисков: штрафы за утечку коммерческой тайны (если бы мы пошли в публичное облако) и экономия на штрафах от надзорных органов благодаря снижению ошибок в проектной документации.
При грамотном расчете NPV выходит положительным, и проект окупается.
4. Практика: что ИИ реально может делать на заводе?
На базе моих тестов и прототипов можно выделить следующие сценарии применения в air-gapped контуре:
Парсинг и аудит техзаданий по ГОСТ 34 и ГОСТ 19
Инженеры загружают в систему сырые требования заказчика. Агенты автоматически разбивают их на атомарные пункты, проверяют на противоречия (через динамику Хегсельмана-Краузе) и генерируют драфты ТЗ, спецификаций и программ испытаний, строго форматированные по ГОСТам. То, на что уходили недели рутины, может делаться за часы.
Анализ нормативной документации (RAG-система)
Сборка локальной базы векторного поиска по внутренним СТО, регламентам и инструкциям. Технолог спрашивает: «Какой допуск по шероховатости для детали Х при обработке на станке Y согласно регламенту от 2023 года?». Модель выдает точный ответ с прямой ссылкой на абзац в PDF.
Анализ исторических логов АСУ ТП и журналов дефектов. ИИ (в связке с классическим ML) может анализировать текстовые записи операторов и телеметрию, выявляя скрытые паттерны, предшествующие поломке оборудования.
Оперативное планирование
Планировщик в цехе общается с ИИ-агентом на естественном языке, чтобы перестроить маршрутные карты при внезапной поломке станка. ИИ опрашивает ERP-систему (через API по строгому графу CPN), анализирует свободные мощности и предлагает варианты перестроения плана.
Заключение
Проектирование локального ИИ для сурового энтерпрайза — это не про то, как написать красивый промт. Это про математику, инженерию (сжатие кэшей, расчет СМО), информационную безопасность на уровне мандатного доступа и архитектуру агентов, которые не имеют права на галлюцинации.
Облака — это здорово и удобно. Но когда речь заходит о ядре промышленности, суверенитет и безопасность данных не имеют цены. И, как показывают мои исследования, архитектура локальных ИИ-кластеров сегодня уже способна решать тяжелые производственные задачи, математически обосновывая свою окупаемость.
А как вы решаете проблему ИИ в закрытых контурах? Пытаетесь пробить файрвол к облакам или собираете свои локальные кластеры? Делитесь в комментариях!