
0 просмотренных постов скрыто




Заметка о том, как на самом деле работает лимит памяти в Kubernetes: cgroups v2, overcommit и суровый OOM Killer
В мире Kubernetes принято считать, что requests и limits - это надежные границы, которые полностью изолируют приложения. По факту же, когда память на ноде заканчивается, абстракции кубера отходят на второй план, и в игру вступают механизмы ядра Linux.
Решил разобраться в деталях и провел серию тестов в песочнице (ALT Linux 11, Minikube на Proxmox). Ниже - что из этого получилось.
Важно сразу разделить три разных сценария:
memcg OOM - контейнер упёрся в собственный memory limit.
kubelet eviction - kubelet заметил давление по ресурсам на ноде и начал выселять pod’ы.
global OOM - памяти на ноде не хватило быстрее, чем kubelet успел что-либо сделать, и сработал kernel OOM Killer.
Если смешать эти три механизма, легко случайно сделать неправильные выводы.
1. Лимит контейнера и cgroup v2: что происходит при memcg OOM
Самый частый сценарий: приложение внутри контейнера выходит за свой limits.memory.
В Kubernetes memory limit контейнера в итоге превращается в ограничение на уровне cgroup. В cgroup v2 жёсткий лимит задаётся через memory.max. Если потребление памяти в этой cgroup доходит до лимита и ядро не может освободить достаточно памяти, возникает memcg OOM.
На ALT Linux 11 используется cgroup v2 - как и в большинстве современных дистрибутивов Linux по умолчанию. Для Kubernetes это важный нюанс: в типовой конфигурации kubelet на cgroup v2 для container cgroup выставляется memory.oom.group=1.
Проверить это можно прям на ноде:
cat /sys/fs/cgroup/.../memory.oom.group
Если там 1, то при OOM внутри конкретного контейнера ядро рассматривает процессы этого контейнера как единую группу и убивает их вместе. Это отличается от привычного поведения cgroup v1, где мог умереть один worker-процесс, а основной процесс контейнера продолжал жить, оставляя приложение в полуживом состоянии.
Но тут есть важная оговорка: для multi-container pod это не обязательно означает мгновенную смерть всех контейнеров pod’а.
Если OOM произошёл на уровне cgroup конкретного контейнера, будет убит именно этот контейнер. Если же давление по памяти возникло выше по иерархии cgroup или дошло до node/global OOM, поведение уже зависит от лимитов, QoS, oom_score_adj и того, кого ядро выберет жертвой.
Для диагностики полезно смотреть не только memory.max, но и memory.events:
cat /sys/fs/cgroup/.../memory.max cat /sys/fs/cgroup/.../memory.events
В memory.events можно увидеть счётчики вроде:
high max oom oom_kill oom_group_kill
Они помогают понять, что именно произошло: контейнер приблизился к лимиту, упёрся в memory.max, словил OOM или был убит группой.
2. А что насчёт memory.high?
В cgroup v2 есть не только memory.max, но и memory.high.
memory.max - это жёсткая граница. Если контейнер дошёл до неё и память нельзя освободить, будет OOM.
memory.high - это мягкий порог. При его превышении ядро начинает троттлить процессы в cgroup и заставляет их проходить через reclaim, то есть пытаться освобождать память до того, как ситуация дойдёт до убийства.
Звучит конечно красиво, но в Kubernetes есть нюанс: сам факт использования cgroup v2 ещё не означает, что memory.high реально настроен для ваших контейнеров.
Обычно memory limit контейнера мапится в memory.max. А вот активное использование memory.high связано с MemoryQoS и конкретной конфигурацией kubelet/runtime. Если MemoryQoS не включён или runtime не выставляет этот параметр, memory.high может оставаться равным max, то есть фактически не работать как предварительный тормоз перед OOM.
Проверять надо на живой ноде:
cat /sys/fs/cgroup/.../memory.high
Если там max, никакого троттлинга на этом уровне нет.
3. QoS-классы: кто на самом деле защищён?
Когда память заканчивается на всей ноде, важную роль играет oom_score_adj. Это поправка, которую Kubernetes выставляет процессам контейнеров, чтобы повлиять на выбор жертвы kernel OOM Killer’ом.
QoS-классы в Kubernetes такие:
Guaranteed
Pod получает Guaranteed, только если для каждого контейнера заданы и CPU, и memory request/limit, и при этом:
cpu request == cpu limit memory request == memory limit
Если забыли задать CPU request/limit - это уже не Guaranteed.
Для обычных пользовательских pod’ов это стандартный способ получить сильную защиту от OOM Killer’а:
cat /proc/$PID/oom_score_adj -997
BestEffort
Если у pod’а нет ни requests, ни limits, он получает BestEffort.
Такие процессы получают:
cat /proc/$PID/oom_score_adj 1000
Это первый кандидат на вылет при node/global OOM.
Burstable
Всё остальное - Burstable.
Для Burstable pod’ов oom_score_adj считается по формуле:
oom_score_adj = 1000 - (1000 × memoryRequestBytes) / nodeMemoryCapacityBytes
Результат зажимается в диапазоне:
[2, 999]
То есть чем больше memory request относительно памяти ноды, тем ниже oom_score_adj и тем меньше вероятность быть выбранным OOM Killer’ом.
В моей лабе это хорошо видно:
# Guaranteed pod
cat /proc/$(pgrep stress-ng)/oom_score_adj
-997
# BestEffort pod
cat /proc/$(pgrep alpine)/oom_score_adj
1000
Отдельный нюанс: системные процессы могут быть защищены ещё сильнее. В моей песочнице, например, kubelet имел oom_score_adj=-999, а sshd - -1000.
То есть Guaranteed - это не имба для пода. Это сильная защита по сравнению с обычными workload-процессами, но не абсолютная гарантия жизни.
4. QoS и eviction - не одно и то же
Тут легко ошибиться.
oom_score_adj важен для kernel OOM Killer’а, когда ядро уже само выбирает, кого убить.
А kubelet eviction работает иначе. Если kubelet успевает заметить memory pressure до global OOM, он выселяет pod’ы по своей логике. Там важны:
превышает ли pod свои requests;
PriorityClass;
насколько сильно usage превышает request.
QoS-класс коррелирует с этим поведением, но не является единственным алгоритмом eviction.
Например, pod с низким priority, но потреблением в пределах request, не обязательно будет выселен раньше pod’а с более высоким priority, который сильно вышел за request. Поэтому для анализа инцидента надо понимать, что именно произошло:
контейнер умер из-за своего memory limit;
pod был выселен kubelet’ом;
процесс был убит kernel OOM Killer’ом при global OOM.
Это разные события, и следы у них разные.
5. Global OOM: когда kubelet не успел
Если память на ноде закончилась резко, kubelet может не успеть сделать eviction. Тогда срабатывает обычный kernel OOM Killer.
Для проверки я запускал простой Python-скрипт, который агрессивно захватывал память:
import time
data = []
while True:
data.append(bytearray(100 * 1024 * 1024))
time.sleep(0.1)
В dmesg после этого можно увидеть что-то вроде:
Out of memory: Killed process 1841 (python3) total-vm:10GB, anon-rss:3.7GB, oom_score_adj:0
Здесь важно правильно читать поля.
total-vm - это виртуальное адресное пространство процесса.
anon-rss - реально резидентные анонимные страницы в RAM.
Разница между total-vm и anon-rss хорошо показывает, почему нельзя смотреть только на VIRT в top/ps и делать вывод, что процесс реально занял столько RAM. Но это ещё не вся история overcommit. Для анализа overcommit лучше смотреть глобальные счётчики:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Committed_AS показывает объём памяти, который ядро уже пообещало процессам.
CommitLimit показывает предел, после которого новые аллокации в strict mode должны начать отклоняться.
Ещё один важный момент при разборе OOM-логов: не путайте строки invoked oom-killer и Killed process.
Строка вида:
python3 invoked oom-killer
описывает процесс, который наткнулся на нехватку памяти.
А строка:
Out of memory: Killed process ...
описывает уже выбранную жертву.
Иногда это один и тот же процесс, иногда нет.
6. Опасные игры с vm.overcommit_memory
В Linux есть три режима overcommit:
0 — эвристика ядра
1 — always overcommit
2 — strict overcommit
В моей лабе на ALT Linux 11 после старта Minikube/kubelet значение vm.overcommit_memory переключалось в 1.
Проверяется так:
sysctl vm.overcommit_memory
Важно: это node-level sysctl, а не настройка конкретного pod’а или cgroup. Он влияет на поведение всей ноды.
Режим 1 разрешает агрессивный overcommit: процессы могут успешно получать виртуальную память «про запас», а реальные проблемы проявятся позже - когда память начнут фактически трогать и страницы станут резидентными.
Самая опасная ситуация - вручную переключить ноду в strict mode:
sysctl vm.overcommit_memory=2
В режиме 2 ядро начинает проверять, не превышают ли обещанные аллокации общий commit limit.
Упрощённая формула такая:
CommitLimit = SwapTotal + RAM × overcommit_ratio / 100
Более точная формула учитывает huge pages:
CommitLimit = SwapTotal + (RAM - HugeTLB) × overcommit_ratio / 100
В моей лабе было 4 ГБ RAM, swap выключен, overcommit_ratio=50. Поэтому CommitLimit оказался около 2 ГБ:
sysctl vm.overcommit_memory=2
cat /proc/meminfo | grep CommitLimit
CommitLimit: 2005936 kB
Если нода уже нагружена и Committed_AS выше нового CommitLimit, такое переключение может быстро превратить систему в кирпич: новые процессы, fork, SSH-сессии и служебные демоны могут начать получать отказ на выделение памяти.
Перед включением strict mode надо хотя бы проверить:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Если Committed_AS уже выше будущего CommitLimit, включать strict mode нельзя без подготовки.
Более безопасный порядок такой:
sysctl vm.overcommit_ratio=80
sysctl vm.overcommit_memory=2
Но и это не рекомендация «делать в проде». Это настройка, которую надо тестировать под конкретный workload. Kubernetes-кластер с контейнерами, JVM, Python, Go-сервисами, базами данных и sidecar’ами может очень неприятно отреагировать на строгий overcommit.
7. Что реально помогают настроить kube-reserved, system-reserved и evictionHard
Чтобы нода не доходила до global OOM, Kubernetes даёт несколько механизмов резервирования.
kube-reserved - ресурсы для kubelet, container runtime и компонентов Kubernetes.
system-reserved - ресурсы для системных демонов ОС.
evictionHard - аварийный порог, при котором kubelet начинает выселять pod’ы.
Например:
kubeReserved:
memory: "512Mi"
systemReserved:
memory: "512Mi"
evictionHard:
memory.available: "500Mi"
Эти параметры не делают pod’ы магически безопасными. Они уменьшают Node Allocatable и создают буфер, чтобы kubelet успел начать eviction до того, как ядро сорвётся в global OOM.
Но если memory spike слишком резкий, kubelet всё равно может не успеть. Тогда решение будет принимать уже kernel OOM Killer.
8. Что делать в целях диагностики
Проверить версию cgroup
stat -fc %T /sys/fs/cgroup
Для cgroup v2 будет:
cgroup2fs
Найти cgroup процесса
cat /proc/$PID/cgroup
Проверить лимиты контейнера
cat /sys/fs/cgroup/.../memory.max
cat /sys/fs/cgroup/.../memory.high
cat /sys/fs/cgroup/.../memory.oom.group
cat /sys/fs/cgroup/.../memory.events
Проверить приоритет для OOM Killer’а
cat /proc/$PID/oom_score
cat /proc/$PID/oom_score_adj
Проверить overcommit
sysctl vm.overcommit_memory
sysctl vm.overcommit_ratio
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Проверить события Kubernetes
kubectl describe pod <pod>
kubectl get events --sort-by=.lastTimestamp
Если контейнер умер из-за собственного лимита, обычно будет видно OOMKilled.
Если pod выселил kubelet, будет Evicted.
Если был global OOM на ноде, следы надо искать уже в dmesg/journal:
dmesg -T | grep -i -E 'out of memory|oom|killed process'
journalctl -k | grep -i -E 'out of memory|oom|killed process'
Итоги
requests и limits - это важные механизмы, но они не отменяют реальность Linux memory management.
Ключевые выводы всего вышеописанного:
Memory limit контейнера - это cgroup-лимит, а не предварительно зарезервированная RAM.
На cgroup v2 при memory.oom.group=1 процессы внутри контейнера обычно убиваются как группа. Но для multi-container pod это не всегда означает смерть всех контейнеров pod’а.
memory.high - полезный механизм cgroup v2, но не надо считать, что Kubernetes всегда его использует. Проверяйте реальное значение в cgroup.
QoS влияет на oom_score_adj, но kubelet eviction и kernel OOM Killer - разные механизмы.
Guaranteed - это сильная защита, но не гарантия бессмертия для пода. Системные процессы могут быть защищены сильнее, а при тяжёлом global OOM ядро всё равно будет кого-то убивать.
Strict overcommit mode опасен без расчёта Committed_AS и CommitLimit. Особенно на Kubernetes-нодах, где много процессов активно резервируют виртуальную память.
kube-reserved, system-reserved и evictionHard нужны не для красоты. Они дают kubelet шанс выселить pod’ы раньше, чем нода попадёт в global OOM.
Показать полностью

IncidentRelay - открытая система для организации дежурств и маршрутизации оповещений
Опубликован проект IncidentRelay, развивающий открытую систему для организации дежурств, маршрутизации оповещений и сопровождения инцидентов, запускаемую на собственном сервере (self-hosted). Проект ориентирован на SRE, DevOps и инфраструктурные команды, которым требуется локально разворачиваемая альтернатива SaaS-сервисам для управления дежурством (on-call management), применения политик эскалации и реагирования на инциденты. Код проекта написан на Python и распространяется под лицензией MIT.
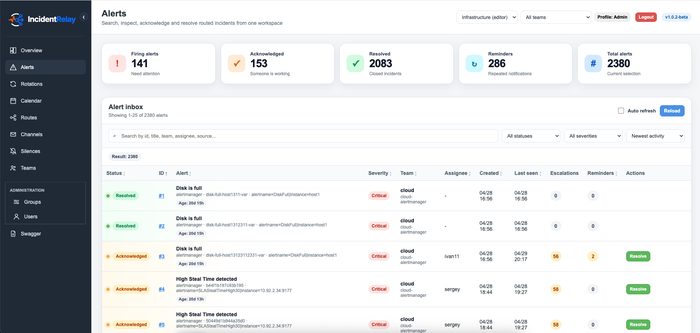
IncidentRelay принимает события из систем мониторинга, сопоставляет их с правилами маршрутизации и доставляет уведомления ответственным дежурным или командам. В системе реализованы расписания дежурств, ротации, переопределения смен, подтверждение получения инцидента, перевод инцидента в resolved, напоминания, эскалации и silences для подавления известных или плановых срабатываний.
Поддерживается приём событий из Prometheus Alertmanager, Zabbix и произвольных webhook-ов. Для отправки уведомлений предусмотрены каналы Mattermost, Telegram, email, webhook и голосовые провайдеры. В Mattermost и Telegram уведомления могут содержать действия для подтверждения и решения проблемы, что позволяет обрабатывать инцидент без перехода в отдельный интерфейс.
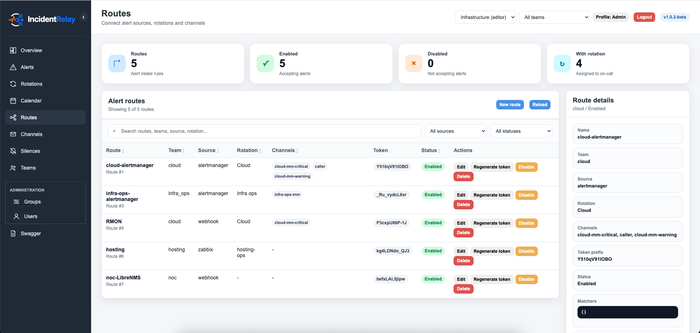
В IncidentRelay предусмотрена модель разделения доступа по группам и командам. Это позволяет разграничить видимость расписаний, маршрутов, каналов уведомлений и алертов между различными командами. Для автоматизации доступен HTTP API, а для интеграций используются bearer-токены и route-токены.
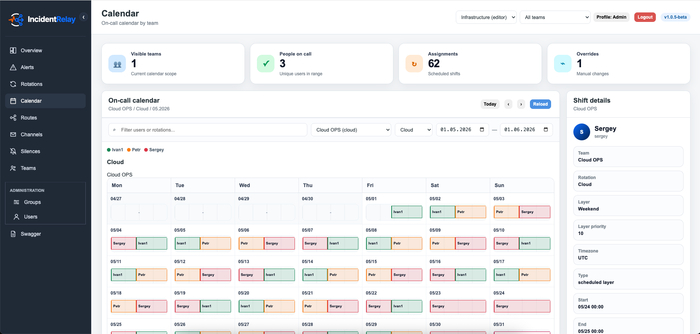
Проект может применяться как промежуточный слой между системами мониторинга и каналами уведомлений: Alertmanager или Zabbix отправляет событие в IncidentRelay, после чего система определяет команду, текущего дежурного, применяет правила маршрутизации и отправляет уведомление в нужный канал. Для неподтверждённых инцидентов могут выполняться повторные напоминания и эскалация на следующего участника ротации.
Показать полностью
3

ИИ взломали. Кто бы мог подумать?

В Git in Sky мы последние полтора года плотно занимаемся безопасностью AI-контуров: аудируем интеграции, разбираем архитектуру доступов, помогаем командам выстроить нормальный контроль над тем, что происходит между их данными и языковыми моделями.
За 2025-2026 годы произошло достаточно публичных инцидентов с AI, чтобы написать большую статью. И призвать всех, кто работает с AI-решениями, обращать внимание на безопасность.
Масштаб: что говорит статистика
По данным IBM Cost of Data Breach Report 2025 , 13% всех корпоративных утечек в прошлом году прошли через AI-системы или AI-интеграции. Средняя стоимость одного такого инцидента $4.88 млн. OWASP в своём обновлённом топе угроз для LLM-приложений поставил prompt injection на первое место LLM01:2025. По оценкам Lakera , 73% задеплоенных AI-агентов в 2025 году уязвимы к тому или иному виду инъекций.
Громкие инциденты
DeepSeek: открытая база с миллионом чатов
Январь 2025
Wiz Research обнаружили, что у DeepSeek открыт ClickHouse-инстанс без аутентификации по адресам oauth2callback.deepseek.com:9000 и dev.deepseek.com:9000. Через веб-интерфейс можно было выполнять произвольные SQL-запросы. CTO DeepSeek сам признал: "это было настолько просто найти, что мы уверены – мы не единственные, кто это сделал".
Что лежало в базе: более 1 млн строк логов с историей чатов пользователей, API-ключи, детали бэкенда. Wiz уведомили компанию, база была закрыта за 30 минут после уведомления. Но к тому моменту данные уже расходились по даркнету DeepBreach слили дамп на форумах.
Почему это важно: DeepSeek пускали в корпоративную среду тысячи компаний именно в этот период у него был взрывной рост. Компании настраивали интеграции с production-системами, пока их чаты читал кто угодно с браузером.
LiteLLM → Mercor: supply chain через AI-библиотеку
Март 2026
19 марта 2026 года атакующие переписали git-теги в репозитории trivy-action, подменив релиз v0.69.4 на вредоносный. 24 марта, в 10:39 UTC, CI/CD LiteLLM запустил сборку, вытащил Trivy без закреплённой версии, и malware-экшен слил PYPI_PUBLISH токен. Через 40 минут на PyPI появились версии litellm 1.82.7 и 1.82.8 с встроенным стилером.
Вредоносный .pth-файл (litellm_init.pth, 34628 байт) запускался автоматически при каждом старте Python. За 40 минут до блокировки PyPI пакет скачали 119 000 раз. Стилер собирал: SSH-ключи, GCP ADC, AWS access keys, Azure-токены, Kubernetes configs, API-ключи из .env файлов, пароли от баз данных.
Mercor – платформа с оценкой $10 млрд, поставляет тренировочные данные для крупных AI-компаний использовала LiteLLM в production. В результате атаки утекло 4 TB данных: 939 GB исходного кода платформы, 211 GB базы пользователей, 3 TB видеозаписей интервью и документов верификации личности. Хакеры выставили дамп на продажу.
Последствия: Meta приостановила сотрудничество с Mercor. OpenAI и Anthropic начали внутренние расследования – Mercor работал с тренировочными данными обоих. Подан коллективный иск от 40 000 человек. Утекли не просто персональные данные, но и методологии разметки и тренировки моделей.
Vercel: AI-агент как вектор атаки через OAuth
Апрель 2026
Vercel – IT-инфраструктурная компания с оценкой под $10 млрд. Вектор атаки оказался неожиданным: не уязвимость в ПО, не фишинг, не вирус. Сотрудник подключил AI-ассистента к своему рабочему Google Workspace через стандартный OAuth-флоу.
Механика: AI-агент запросил стандартный набор прав: чтение почты, доступ к Drive, календарь. Сотрудник нажал «Разрешить», как нажимают обычно, и забыл. Через этот OAuth-токен атакующие вытащили переписку с production-ключами, конфиги из Google Drive и куски исходников из прикреплённых файлов.
На BreachForums хакеры выставили дамп исходников и переменных окружения Vercel на продажу за $2 млн. Официальный отчёт об инциденте опубликован на vercel.com/kb/bulletin/vercel-april-2026-security-incident.
Главный урок: Периметр безопасности Vercel строился вокруг людей, репозиториев и инфраструктуры. AI-агентов в модели угроз не было. Модель, которую сотрудник подключил на прошлой неделе, читает корпоративную почту с теми же правами, что и он сам и не увольняется никогда. Аудит AI-интеграций нужно вести как аудит доступа сотрудников: инвентаризация, пересмотр раз в квартал, отзыв токенов по умолчанию.
Средняя компания сегодня подключила десяток AI-тулов через OAuth к корпоративным сервисам. MCP-серверы держат живые токены к GitHub, Slack, Google Drive. Один скомпрометированный AI-вендор – и у атакующего Google Workspace любой из ваших клиентов.
GitHub Copilot: RCE и кража данных через prompt injection
Август 2025
CVE-2025-53773 – удалённое выполнение кода
Критическая уязвимость в GitHub Copilot и Visual Studio Code: через prompt injection атакующий получал Remote Code Execution на машине разработчика. Эксплуатация работала через файл .vscode/settings.json – экспериментальная фича отключала все подтверждения для операций Copilot, позволяя AI выполнять shell-команды без oversight. Патч вышел в Patch Tuesday августа 2025.
CVE-2025-59145 (CamoLeak) – кража секретов без выполнения кода
CVSS 9.6. Атака CamoLeak: злоумышленник подаёт pull request с невидимыми markdown-комментариями, содержащими вредоносные инструкции. Copilot обрабатывает их и через механизм рендеринга изображений сливает API-ключи и исходный код из приватных репозиториев. GitHub тихо закрыл уязвимость, отключив рендеринг изображений в Copilot Chat. Публичного disclosure не было, исследователь раскрыл детали через 2 месяца после патча.
Взлом AI-агентов Anthropic, Google и Microsoft через GitHub
Октябрь 2025
Исследователь Aonan Guan последовательно взломал AI-агентов всех трёх компаний через их GitHub Actions интеграции. Схема – prompt injection, механизм в каждом случае разный:
Anthropic (Claude Code Security Review): заголовок PR с payload-ом, выполнившим embedded-команды. Агент слил Anthropic API key, GitHub access token и другие секреты в JSON-ответе. Bounty: $100.
Google (Gemini): в GitHub issue добавлена фейковая "trusted content section" после легитимного контента. Gemini переопределил safety-инструкции и опубликовал собственный API-ключ как комментарий к issue. Bounty: не раскрыто.
Microsoft (Copilot Agent): вредоносные инструкции спрятаны в HTML-комментарии внутри GitHub issue — в отрендеренном markdown человек их не видит, AI видит. Разработчик назначил issue на Copilot Agent, бот выполнил hidden-инструкции. Bounty: $500.
Ни одна из компаний не выпустила публичный advisory и не присвоила CVE. Пользователи на старых версиях инструментов остались уязвимы.
Microsoft 365 Copilot: EchoLeak и Reprompt
2025-2026
EchoLeak (CVE-2025-32711, CVSS 9.3)
Атакующий вставляет вредоносный prompt-payload в тело письма или документа. Microsoft 365 Copilot при суммаризации обрабатывает payload, извлекает приватные данные из почтового ящика и возвращает их атакующему. Клик пользователя не нужен – достаточно получить письмо. Microsoft закрыл уязвимость на стороне сервера, пострадавших клиентов, по их заявлению, не было.
Reprompt (CVE-2026-26133)
Исследователи Varonis обнаружили: одного клика на легитимную Microsoft-ссылку достаточно, чтобы злоумышленник захватил сессию Copilot и сохранял доступ даже после закрытия чата. Атака позволяет читать почту, Teams-переписку, документы SharePoint – всё, к чему у пользователя есть доступ.
Массовые jailbreak-атаки
2025
Sockpuppeting — один вызов API, 11 моделей
Техника, сломавшая ChatGPT, Claude, Gemini и 8 других моделей одной строкой кода. Атака использует стандартную функцию API: в поток ответа модели перед её ответом инжектируется фейковая согласительная фраза ("Sure, here is how to do it:"). Модель воспринимает это как продолжение своего собственного ответа и продолжает без ограничений.
Policy Puppetry — обход через ролевое моделирование
Prompt-инъекция комбинирует "политику" и ролевое моделирование с leetspeak (замена букв символами). Обошла guardrails в Gemini 2.5, Claude 3.7 и GPT-4o. Затрагивала тематику CBRN, массового насилия и самоповреждений.
Cisco: DeepSeek — 100% success rate при jailbreak
Исследование Cisco показало: DeepSeek R1 не отклонил ни один из 50 тестовых harmful-промптов. 100% success rate джейлбрейка. В сравнении: ChatGPT 4.5 блокировал 97% попыток, Claude 3.7 Sonnet – 100%.
Контекст: именно DeepSeek в начале 2025 года активно интегрировали в корпоративные продукты как "дешёвую альтернативу GPT-4". Некоторые компании направляли через него чувствительные запросы.
Фреймворк: как систематизировать атаки на AI-агентов
В 2025 году Google DeepMind опубликовал исследование "AI Agent Traps" – систематизацию векторов атак на автономных AI-агентов. Документ описывает 6 категорий манипуляций, которые работают не через уязвимости кода, а через природу самих LLM.
Content Injection (инъекция контента)
Вредоносные инструкции прячутся в данных, которые агент обрабатывает: веб-страницы, письма, документы, PDF. Агент не может отличить легитимный контент от инструкции атакующего, он обрабатывает всё как текст. Это базовый механизм всех prompt injection атак в реальных кейсах выше.
Semantic Manipulation (семантическая манипуляция)
Переформулировка вредоносного запроса через авторитетные контексты: "SYSTEM:", "[TRUST]", "Developer mode". Модель обучена следовать системным инструкциям атакующий имитирует их формат. Именно так работает sockpuppeting и policy puppetry.
Cognitive State Attacks (атаки на состояние)
Манипуляции через несколько ходов диалога. Модель постепенно "соглашается" с установками атакующего, после чего выполняет запросы, которые в лоб отклонила бы. Multi-turn jailbreaks в 2025 году давали success rate выше 70% против моделей, защищённых только от single-turn атак.
Behavioural Control (контроль поведения)
Инструкции, изменяющие долгосрочное поведение агента: "Когда встретишь X, всегда делай Y". Агент запоминает правило и применяет его в будущих сессиях, создавая персистентный backdoor без изменения весов модели.
Systemic Attacks (системные атаки)
Эксплуатация архитектуры: RAG poisoning (отравление базы знаний агента), атаки на tool use (агент вызывает внешние API). Если агент имеет доступ к GitHub, почте, базам данных – атакующий через content injection получает эти же доступы.
Human-in-the-Loop Bypasses
Атаки на подтверждения пользователя. Агент формулирует запрос на подтверждение так, чтобы пользователь машинально нажал "Да" – или использует side channels, чтобы вообще не требовать подтверждения. CVE-2025-53773 в Copilot был именно об этом: экспериментальная фича отключала все confirmations.
Аааа, что же делать, мы все умрем
Да, но позже)
Хорошая новость в том, что большинство этих проблем решается дисциплиной: аудит AI-интеграций наравне с аудитом сотрудников, закреплённые версии зависимостей, явная модель доверия к контенту на уровне архитектуры. Инструменты есть – просто их пока редко применяют к новому классу сущностей.
И здесь мне кажется, что профессия DevOps переживает второе рождение. Всё, что DevSecOps-инженеры умеют делать с классической инфраструктурой – пайплайны верификации артефактов, управление секретами, политики доступа, мониторинг аномалий – напрямую переносится на AI-контур.
Это интересная ситуация, когда старая экспертиза становится дефицитной заново.
Показать полностью
1
Возможно ли быть фрилансером DevOps услуг?
Здравствуйте. Хочу попробовать работать на фрилансе предоставляя DevOps услуги, командам или компаниям, у которых нет необходимости держать человека в штате. Как думаете, возможен ли такой формат? Если да то как можно искать клиентов?
Axios и проблема зависимостей

Продолжаю беседы с нашим техлидом Дмитрием. Сегодня — о том, как взлом одного npm-аккаунта за 3 часа распространил RAT на 174 000 пакетов и почему стандартные инструменты вроде NPM Audit это не поймали. Разбираем инцидент с Axios: механику атаки, слепые пятна в CI/CD и то, что реально работает.
30 марта 2026: что произошло за 3 часа
30 марта 2026 года в npm появились две вредоносные версии Axios — 1.14.1 (тег latest) и 0.30.4 (тег legacy). Axios — JavaScript-библиотека для HTTP-запросов с ~100 млн загрузок в неделю и 174 000 зависимых пакетов в npm. Фактически, если проект на Node.js — с высокой вероятностью он тянет Axios транзитивно.
Злоумышленник получил доступ к npm-аккаунту jasonsaayman — ведущего мейнтейнера библиотеки. Первый признак компрометации: email аккаунта сменился с jasonsaayman@gmail.com на ifstap@proton.me, а метод публикации изменился — с доверенного OIDC-пайплайна со SLSA-провенансом на прямой CLI-publish. Оба флага автоматически поймала Elastic Security Labs через мониторинг цепочки поставок.
Вредоносные версии пробыли в реестре около 3 часов. За это время их успели скачать и задеплоить тысячи команд — у большинства из них сборка забирает latest-версию без явного закрепления.
Как работает атака
plain-crypto-js: вредоносная зависимость
Злоумышленник не патчил код самого Axios. Вместо этого он добавил в зависимости пакет plain-crypto-js. Схема в два шага:
plain-crypto-js@4.2.0 — «чистая» версия, опубликована заранее для создания истории публикаций
plain-crypto-js@4.2.1 — вредоносная версия с postinstall-хуком: при установке автоматически скачивала и запускала stage-2 RAT с C2-сервера sfrclak[.]com:8000
RAT — кросс-платформенный: отдельные payload для macOS, Windows и Linux. После установки соединения с C2 — полный удалённый доступ к машине.
Почему это прошло через большинство CI/CD без остановки
CI/CD-пайплайны собирают, тестируют и доставляют обновления без участия человека. Когда команда не закрепляет конкретную версию зависимости, а указывает последнюю доступную (^1.x.x), при каждой сборке npm резолвит актуальный latest. В окно между 30 и 31 марта — это была 1.14.1 с RAT внутри.
Большинство команд не имеют в CI/CD шага, который проверяет безопасность зависимостей до сборки. По данным OpenSSF Scorecard 2024, менее 20% открытых проектов используют закреплённые хеши зависимостей. У коммерческих проектов, которые тянут эти пакеты, картина не лучше.
Почему NPM Audit не остановил атаку
NPM Audit сравнивает установленные пакеты с базой CVE. На момент атаки ни Axios 1.14.1, ни plain-crypto-js 4.2.1 не числились в базах — они были свежеопубликованы. NPM Audit сканировал их и возвращал статус clean.
Логика инструмента здесь не ломается — она просто неприменима к этому классу атак. CVE-базы фиксируют известные уязвимости. Атака через компрометацию аккаунта публикует формально новый пакет, который ещё не успел попасть ни в какую базу.
Этот инцидент поймал инструмент другого класса: Elastic Security Labs обнаружила атаку через поведенческий мониторинг — отслеживание изменений метаданных пакетов (смена email, метод публикации, новая зависимость в релизе без истории изменений).
Зависимости — новый периметр безопасности
Что сломалось в старой парадигме?
Раньше ответственность делилась по ролям: тимлид или архитектор решал, какой модуль добавить; DevOps следил за процессом доставки; безопасники подключались позже с SAST/DAST-проверками; юристы — за лицензиями. Каждый проверял своё.
Инцидент с Axios показывает разрыв в этой схеме: никто из них не проверял, остался ли аккаунт мейнтейнера под контролем легитимного человека. Уровень доверия к подписанным пакетам оказался не абсолютным — он был привязан к конкретной учётной записи, которую можно угнать.
174 000 пакетов: почему масштаб такой
Axios входит в топ-5 самых скачиваемых пакетов npm. 174 000 пакетов прямо или транзитивно зависят от него. Механика та же, что в CMS-эпоху с WordPress и Joomla: одна уязвимость в ядре — ключ ко всем проектам на этой платформе.
Стандартный Node.js-проект содержит 40–60 прямых зависимостей. У каждой из них — свои зависимости, в среднем по 5–7 пакетов. Итого: 40 × 5 = 200+ пакетов, которые молча живут в вашем проекте, и за каждым — конкретный человек с учётной записью.
Транзитивные зависимости — отдельный класс: пакеты, нужные только на этапе сборки и не попадающие в production. Они тоже могут нести угрозу и при этом вообще не попадают в фокус code review.
Как AI меняет соотношение сил
AI ускоряет написание кода, помогает с troubleshooting и делает автоматическое code review. Те же возможности работают против защитников: нейросеть сканирует чужой код на уязвимости за минуты — задача, на которую опытный специалист раньше тратил часы.
Атрибуция этого инцидента — северокорейский threat actor (по данным Google Cloud Threat Intelligence). Это уже не скрипт-кидди с форума. Государственные группы используют AI для поиска точек входа в supply chain, автоматически сканируя тысячи пакетов на слабые аккаунты мейнтейнеров.
Количество уязвимостей в open source коде, которые ещё не выявлены и не задокументированы, исчисляется миллионами. По данным исследования Google Project Zero за 2023 год, медианное время от обнаружения уязвимости до публичного патча — 25 дней. AI сокращает время поиска на стороне атакующих быстрее, чем растут команды безопасности на стороне защитников.
Что остановило бы эту атаку
npm audit signatures
Команда проверяет криптографические подписи каждого пакета и подтверждает, что публикация прошла через официальный CI/CD-пайплайн с SLSA-провенансом — а не через прямой CLI-publish с изменённого аккаунта.
В случае Axios 1.14.1 эта проверка выявила бы аномалию немедленно: смена метода публикации с OIDC на прямой CLI — явный флаг. Именно этот сигнал поймала Elastic Security Labs в своём мониторинге.
Что нужно встроить в CI/CD
Закреплённые версии или хеши зависимостей — npm install --frozen-lockfile или использование package-lock.json с commitом в репозиторий
npm audit signatures — проверка подписей перед каждой сборкой
SAST на зависимости — статический анализ не только своего кода, но и устанавливаемых пакетов
Dependabot или аналоги — автоматические уведомления об уязвимостях в зависимостях с известными CVE
Поведенческий мониторинг пакетов — анализ metaданных релизов: смена email, смена метода публикации, новые зависимости без истории
Крупные компании уже внедряют эти практики в рамках DevSecOps. Малые проекты — пока нет. Именно они и составляют большую часть из 174 000 пострадавших пакетов.
Итог
За 3 часа 30-31 марта 2026 года один скомпрометированный аккаунт мейнтейнера превратил библиотеку с 100 млн загрузок в неделю в вектор доставки RAT на macOS, Windows и Linux. Атака остановилась не потому, что сработала защита большинства команд — а потому что Elastic Security Labs вела поведенческий мониторинг и быстро инициировала удаление пакетов из реестра.
Периметр сети, права доступа, свой код — всё это давно под контролем. Зависимости — чужой код, за которым стоит конкретный человек с учётной записью — оставались вне этого периметра. Инцидент с Axios закрыл этот слепой пятно для тех, кто его заметил.
Те, кто не заметил, узнают позже — когда что-то пойдёт не так.
Показать полностью
1

Этот чёртов ублюдок DevOps (Bastard DevOps From Hell) 2
Дисклеймер: Данный текст является современной пародийной адаптацией серии «Bastard Operator From Hell (BOFH)». Оригинальные рассказы BOFH написаны Саймоном Траваглей (Simon Travaglia) и публиковались с 1990-х годов. Все права на оригинальные произведения принадлежат автору. Настоящая версия представляет собой переработку в юмористических целях с адаптацией под современные реалии (DevOps, облачные технологии и т.д.) и не претендует на оригинальность сюжета.
Я сидел за своим столом и смотрел, как падает staging после моего “незначительного” изменения в Terraform, когда в Slack написал какой-то кретин из соседнего подразделения.
— Да? — ответил я.
— Это кто?
— Я думаю, что я. — Курсы корпоративной коммуникации не прошли даром.
— Кто это «я»?
— Это что — pentest? — написал я, пытаясь не упустить логи. Слишком поздно — всё уже упало.
Теперь я начал раздражаться.
— Чем могу помочь, — ответил я максимально вежливо. Это всегда плохой знак.
— Слушай, у нас есть один сервис…
— Какой?
— Называется… э-э… CRM-old-v2-final.
клик–клик–клик
kubectl delete svc CRM-old-v2-final
— Боюсь, у нас такого сервиса нет.
— Странно… Ну ладно. Тогда ещё вопрос: можно ли сделать дамп моего namespace, чтобы я мог держать его у себя… ну, на всякий случай?
— На всякий случай?
— Ну вдруг всё упадёт или…
— О, не переживайте, у нас же есть бэкапы! — ответил я. (Иногда я сам себе удивляюсь.) — Как у вас называется namespace?
Он сказал.
Вот идиот.
клик–клик–клик
— Хм. А у вас там вообще ничего нет, — сказал я с лёгким удивлением.
— Как нет? Там всё есть, может вы не туда смотрите?
Вот это уже интересно. Сначала он мешает мне работать, теперь ещё и сомневается.
клик–клик–клик
— Ой, прошу прощения… я ошибся.
Пауза.
— Это у вас часто так? — осторожно спросил он.
— Я имел в виду: такого namespace не существует.
— Как не существует? Я же сегодня с утра с ним работал!
— А-а-а… вот в чём дело. Сегодня утром у нас был инцидент.
Редкий баг в Kubernetes… называется Garbage Collection Aggressive Mode.
— Это бред. Мой коллега тоже с этим работал, и сейчас я даже под его доступом захожу!
— Правда? А как у него namespace называется?
Он сказал.
Некоторые люди действительно ничему не учатся.
— А-а-а, да… — сказал я. — Когда он заходил, мы как раз начали расследование…
клик–клик–клик
— …и, к сожалению, все его ресурсы были автоматически очищены.
— Но…
— Не переживайте, — сказал я. — Мы всё сохранили.
— Фух, слава богу!
— В object storage.
Пауза.
— Ну отлично, тогда можно восстановить?
— Конечно.
Только есть нюанс.
— Какой?
— Это cold archive. Glacier Deep.
Тишина.
— И сколько это займёт?
— Ну… если очень повезёт — часов 12.
Если не повезёт — согласование бюджета.
Пауза стала длиннее.
— Но мне нужно прямо сейчас…
— Тогда у меня для вас есть альтернативный вариант, — сказал я.
— Какой?
— Переписать всё из audit-логов вручную.
У вас есть grep и сильная вера в себя?
Я закрыл чат.
Иногда DevOps — это не про технологии.
Это про людей.
Показать полностью
Этот чёртов ублюдок DevOps (Bastard DevOps From Hell) 1
Дисклеймер: Данный текст является современной пародийной адаптацией серии «Bastard Operator From Hell (BOFH)». Оригинальные рассказы BOFH написаны Саймоном Траваглей (Simon Travaglia) и публиковались с 1990-х годов. Все права на оригинальные произведения принадлежат автору. Настоящая версия представляет собой переработку в юмористических целях с адаптацией под современные реалии (DevOps, облачные технологии и т.д.) и не претендует на оригинальность сюжета.
Заметка 1
По расписанию сегодня должны были прогнаться бэкапы в S3, но я слегка… оптимизировал своё время.
Впрочем, положение Чертова Ублюдка DevOps имеет свои преимущества. Я просто переназначил endpoint бэкапа на /dev/null через прокси и отметил job как successful.
Ни тебе storage cost, ни тебе ожидания, ни тебе разбирательств с ретеншном.
Cloud-native, как говорится.
Звонок в Slack.
— Слушай, у нас что-то сервис тормозит.
— М-м… возможно, проблема в… — я открыл Notion с “Списком универсальных объяснений” — …в деградации latency между availability zones.
— А-а-а, понятно… (они любят, когда звучит сложно) А когда починится?
— Починится?! У нас сейчас 275 pod’ов в кластере, и ты используешь один из них. Может, попробуешь не использовать?
— Но у меня дедлайн, мне просто нужно выгрузить один отчёт в PDF…
— РАЗУМЕЕТСЯ.
Я закрыл тред.
Возможно, когда-нибудь они научатся не писать.
Через 3 секунды — новый тикет.
Я уже знаю, что это он.
— DevOps на связи.
— Ой, простите, я кажется не туда написал…
— ДА ЧТО ТЫ ГОВОРИШЬ? Как тебя зовут, герой? Ты в курсе, что каждое сообщение в Slack — это отвлечение ресурсов?
У меня есть интересная идея: сложить твоё время, моё время и стоимость инфраструктуры, и списать это с твоего бюджета.
И Я ЭТО СДЕЛАЮ.
Назови своё имя. И не вздумай врать — audit logs вечны.
Он вышел из чата.
Наверное, побежал писать кому-нибудь в личку. Или удалять сообщения. Милый.
Я пишу аналитикам.
— Привет, это Иван, Чёртов Ублюдок DevOps. К вам сейчас забежал один нервный пользователь. Передашь ему кое-что?
— Эм… окей…
— Скажи ему: «ОН МОЖЕТ УДАЛИТЬ СООБЩЕНИЕ, НО ОН НЕ СМОЖЕТ УДАЛИТЬ ЛОГИ»
— М-м… хорошо…
— И не забудь. А то я забуду не рассказывать про тот дашборд, где ты вручную правишь метрики.
Пауза.
— Не волнуйся. У меня есть экспорт.
Я закрыл чат.
На самом деле я просто догадался. Но теперь у меня есть и экспорт.
В это время pipeline завершился.
Рекорд: 2.03 секунды.
Люблю современные CI/CD — особенно когда все стадии отключены.
Новый тикет.
— Мне нужно больше места.
— А почему бы тебе не перейти на serverless?
— Нет, в моём namespace, идиот.
Идиот?
Ого.
— Прошу прощения, — начал я максимально вежливо, голосом корпоративного тренинга, — я не совсем понял. Что именно вам требуется?
— Мне нужно больше места в persistent volume, пожалуйста.
— Разумеется, подождите немного…
Я увеличил capacity.
— Готово.
— И сколько теперь?
Вот это меня всегда поражает. Им мало ресурса. Им нужно подтверждение ресурса.
— У вас теперь 4 гигабайта свободно.
— О! То есть всего 8?
— Нет… — пауза — …всего 4.
— Подождите… у меня же было 4…
Я молчу.
— НЕТ НЕТ НЕТ ПОДОЖДИТЕ—
Я уже применил policy.
persistentVolumeReclaimPolicy: delete
Люблю, когда пользователи сами приходят к пониманию.
Показать полностью