
Помощь с Microsoft Excel
всем привет
как оставить сумму в формуле Microsoft Excel без слагаемого?
например 2+2=4
если убрать одну из двоек то пропадёт и 4
а мне надо чтобы осталась 4 в столбце
всем привет
как оставить сумму в формуле Microsoft Excel без слагаемого?
например 2+2=4
если убрать одну из двоек то пропадёт и 4
а мне надо чтобы осталась 4 в столбце
А я с PowerBI могу помочь. Дизайн, оптимизация моделей, dax. Насколько позволит формат комментов, конечно.
Вообще если есть потребность, сигнальте - были мысли начать просветительской деятельностью в этом направлении заниматься (массово и бесплатно), если будет спрос, начну писать/снимать.
Раз пошла такая пьянка, то:
Ну может кому надо - смогу помочь, подсказать, возможно немного объяснить в гугл таблицах, эксель таблицах. Мне кажется все всё уже умеют, но если бы все умели у меня б не было заказов и доп работы)
Если что то простенькое и быстрое то смогу рассказать/объяснить за просто так.
Добра прочитавшим.
В серверной разработке на Python, аналитике данных и задачах автоматизации офисной работы чтение файлов Excel и преобразование их в удобные для программ обработки структуры данных является одной из самых распространённых задач.
Многие разработчики начинают работать с данными таблиц через числовые индексы, например row[2] или col[5]. Хотя такой подход позволяет быстро приступить к разработке, он приводит к серьёзной проблеме жёсткой привязки к строкам и столбцам. Код становится сложнее для чтения и поддержки, а любое изменение структуры таблицы — например, перестановка, добавление или удаление столбцов — может нарушить работу значительной части приложения.
В этой статье мы воспользуемся библиотекой Free Spire.XLS for Python, чтобы показать трёхэтапную эволюцию моделирования данных Excel:
Необработанные двумерные списки
Списки словарей
Списки пользовательских бизнес-объектов
Каждый подход подходит для определённых сценариев и уровней сложности. Отказавшись от жёстко заданных индексов, вы сможете сделать код обработки Excel более читаемым, поддерживаемым и масштабируемым.
Во всех примерах статьи используется пакет spire.xls, который позволяет читать, записывать, форматировать и пакетно обрабатывать файлы Excel без установки Microsoft Excel.
Установите библиотеку командой:
pip install spire.xls.free
Это самый простой способ чтения данных Excel. Мы последовательно перебираем используемый диапазон листа по строкам и ячейкам, сохраняя все данные в двумерный список, который полностью повторяет структуру исходной таблицы.
from spire.xls import Workbook
# Загружаем книгу и рабочий лист
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
# Получаем используемый диапазон
cell_range = sheet.AllocatedRange
# Сохраняем все данные в двумерный список
excel_data = []
for row_idx in range(cell_range.RowCount):
single_row = []
for col_idx in range(cell_range.ColumnCount):
# В Spire.XLS используются индексы, начинающиеся с 1
single_row.append(
cell_range[row_idx + 1, col_idx + 1].Value
)
excel_data.append(single_row)
# Освобождаем ресурсы
workbook.Dispose()
Преимущества
Максимально простая реализация
Полностью сохраняет исходную структуру строк и столбцов
Не требует дополнительного преобразования данных
Недостатки
Доступ к данным осуществляется только через числовые индексы:
excel_data[row][col]
Такой код не несёт смысловой нагрузки. Если структура таблицы изменится, все ссылки на индексы придётся обновлять вручную, что усложняет поддержку и повышает риск ошибок.
Подходит для
Быстрых прототипов
Одноразовых скриптов
Матричных вычислений
Временного анализа данных
Для производственных приложений такая структура обычно не является оптимальным решением.
Чтобы избавиться от жёстко заданных индексов столбцов, можно использовать первую строку как заголовки столбцов и преобразовать каждую последующую строку в словарь.
Вместо доступа к данным по позиции мы получаем доступ по имени поля. Это устраняет зависимость от порядка столбцов и значительно улучшает читаемость кода.
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("SalesReport.xlsx")
sheet = workbook.Worksheets[0]
cell_range = sheet.AllocatedRange
# Извлекаем заголовки из первой строки
rows = list(cell_range.Rows)
headers = [
cell_range[1, col_idx + 1].Value
for col_idx in range(cell_range.ColumnCount)
]
# Формируем список словарей
data_list = []
for row in rows[1:]: # Пропускаем строку заголовков
row_dict = {}
for idx, cell in enumerate(row.Cells):
row_dict[headers[idx]] = cell.Value
data_list.append(row_dict)
workbook.Dispose()
Преимущества
Теперь данные можно получать по понятным именам полей:
data_list[0]["Sales"]
Преимущества такого подхода:
Более высокая читаемость кода
Независимость от порядка столбцов
Простая сериализация в JSON
Удобная интеграция с API и конвейерами обработки данных
Хорошая совместимость с Pandas
Недостатки
Структуры на основе словарей по-прежнему являются слабо типизированными. Перед использованием данных может потребоваться дополнительная проверка и преобразование типов.
Подходит для
Импорта и экспорта данных
Очистки и подготовки данных
Генерации полезной нагрузки для API
Бизнес-отчётности
Универсальной обработки Excel
Для большинства приложений это оптимальный баланс между простотой и удобством сопровождения.
При работе с фиксированными схемами данных и более сложной бизнес-логикой словари могут оказаться недостаточно удобными. Они не обеспечивают типобезопасность, поддержку IntelliSense и не предоставляют естественного места для размещения бизнес-правил.
Более надёжный подход заключается в создании класса бизнес-сущности и преобразовании каждой строки Excel в экземпляр этого класса.
В результате получается строго типизированная модель, поддерживающая валидацию, бизнес-методы и более удобные инструменты разработки.
# Определение бизнес-сущности
class Employee:
def __init__(self, name: str, age: int | None, department: str):
self.name = name
self.age = age
self.department = department
def is_adult(self) -> bool:
"""Возвращает True, если сотрудник является совершеннолетним."""
return self.age >= 18 if self.age else False
from spire.xls import Workbook
workbook = Workbook()
workbook.LoadFromFile("EmployeeData.xlsx")
sheet = workbook.Worksheets[0]
cell_range = sheet.AllocatedRange
employee_list = []
# Пропускаем строку заголовков
for row in list(cell_range.Rows)[1:]:
name = row.Cells[0].Value
age = (
int(row.Cells[1].Value)
if row.Cells[1].Value
else None
)
department = row.Cells[2].Value
employee = Employee(
name,
age,
department
)
employee_list.append(employee)
workbook.Dispose()
Преимущества
Строгая типизация благодаря явному преобразованию типов
Более качественная проверка данных
Автодополнение и подсказки IDE
Инкапсуляция бизнес-логики
Улучшенная поддерживаемость кода
Более чистый объектно-ориентированный дизайн
Например:
employee.is_adult()
Бизнес-правила могут быть реализованы непосредственно внутри сущности, а не распределены по всему приложению.
Подходит для
Корпоративных приложений
Стабильных и хорошо определённых схем данных
Систем со сложными бизнес-правилами
Долгосрочных проектов, требующих удобной поддержки
Оптимальный выбор зависит от сложности приложения и способа использования данных.
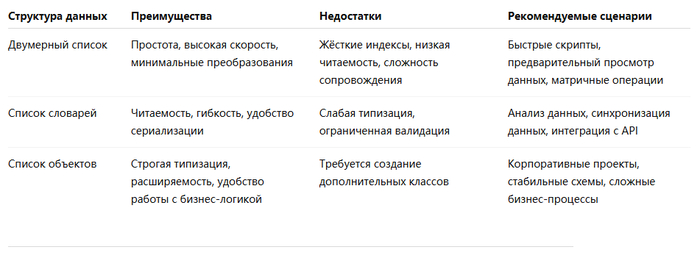
Переход от:
Числовых индексов в двумерных списках
Семантического доступа через словари
Строго типизированных бизнес-объектов
отражает более широкий переход от ориентированного на данные программирования к моделированию, ориентированному на бизнес-логику.
Простые скрипты не требуют сложных абстракций. Для большинства реальных задач обработки Excel список словарей обеспечивает отличный баланс между гибкостью и удобством сопровождения. Если же приложение содержит сложные бизнес-правила и использует стабильные схемы данных, пользовательские объекты-сущности становятся наиболее надёжным долгосрочным решением.
Правильный выбор структуры данных позволяет значительно снизить сложность кода, повысить его читаемость, уменьшить количество ошибок и упростить сопровождение процессов обработки Excel по мере роста проекта.
Key: TQXGF-NR2Y2-92M2F-KPHB8-78WCQ
Description:
Office24_ProPlusVL_MAK_AE2
Remaining:
215+

В очередной раз чутка приуныл, и решил отдышаться, выдав этот узкоспециализированный многобукав скорее даже для себя.
Если брать статику в светопрозрачных конструкциях или НВФ, то 9 из 10 случаев сводятся к одно-пролетной балке (редко 2-х) на шарнирно-неподвижных опорах. Очень выручает маркер, калькулятор и упаковка от обеденной шаурмы. Все довески в виде прогибов заполнений, кронштейнов, крепежа и прочих ягодок вынуждают залезть в шпаргалки в том самом Excel. Для серьезных стержневых есть различные лироскадороботы... Одно отступление: все это справедливо, если ты вообще рубишь в том, чем занимаешься.
Иногда треть дня проходит за отвлечением на: "а такой пакет пройдет?", "а пятерки металла хватит?", "а если ламели навесить, стойка пройдет?"...
Да йобанарот, посчитай, тыжынжынер!
Каждую балку считать и пересчитывать на изменившиеся условия и систему в том же СКАДе и ему подобных, это просто непозволительная роскошь, если это способ зарабатывания на хлеб, а не загон под веществами.
Желание выкроить больше времени, заставляет свести все в какую то мега шпаргалку со всеми статистически хоть раз встречающимися вопросами.
Всем доброго дня. Сегодня поговорим про очень популярные функции.
Каждый, кто хоть раз собирал отчеты в Excel, знает: жизнь делится на "до" и "после" изучения функции ВПР (VLOOKUP). Это как познать дзен. Вы наконец-то перестаете судорожно искать совпадения глазами и копировать их вручную.
Но в Excel 2021 Microsoft выкатила убийцу старых формул — функцию ПРОСМОТРX (XLOOKUP). Многие после этого начали утверждать, что ВПР пора закопать, а связку ИНДЕКС + ПОИСКПОЗ (INDEX + MATCH) — сдать в музей.
В своем новом видео я попытался убедить пользователей, что хоронить старую гвардию еще очень рано. Как говорится, старый ВПР борозды не испортит.
Начнем с хорошего. ПРОСМОТРX — действительно классная штука. Она не требует считать столбцы, не ломается, если вы ищете данные справа налево, и в неё уже встроен "предохранитель" от ошибок (замена ЕСЛИОШИБКА) в виде отдельного аргумента.
Но тут включается суровая офисная реальность: вам нужно заполнить итоговую таблицу из огромной базы. Причем столбцы в вашей таблице идут вразнобой — например, сначала "Статус", потом "Стоимость", а потом "Количество" (а в исходнике порядок другой).
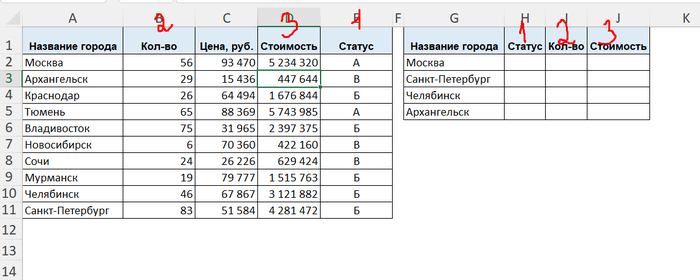
Что делает ПРОСМОТРX: увы, пасует. Вам придется писать формулу отдельно для каждого (!) столбца. Да, её можно настроить и закрепить, но перетаскивать диапазоны вручную для каждой колонки или переписывать — сомнительное удовольствие.
Как отвечает старый добрый ВПР: в связке с функцией ПОИСКПОЗ (MATCH) старина ВПР делает это одной левой. Мы просто заставляем ПОИСКПОЗ автоматически определять номер нужной колонки по её заголовку.
Результат: пишем ровно одну формулу в самую первую ячейку, протягиваем её на всю таблицу (и вниз, и вбок) — и готово! Более того, если завтра ваш коллега решит поменять местами столбцы в исходнике или воткнет туда новую колонку, магия ВПР + ПОИСКПОЗ даже не вздрогнет. Всё пересчитается автоматически.
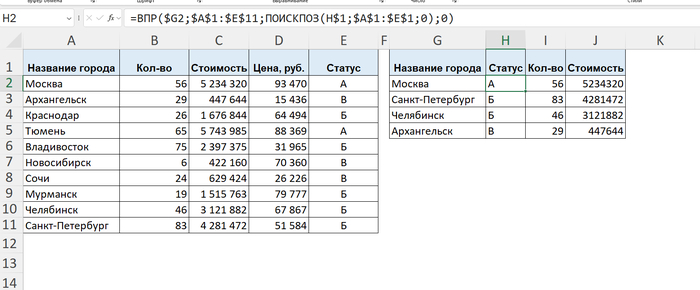
У ПРОСМОТРX есть потрясающая фишка — она умеет выдавать "динамические массивы". Вы указываете ей несколько столбцов, и она мгновенно заполняет сразу несколько соседних ячеек вправо. Выглядит как магия.

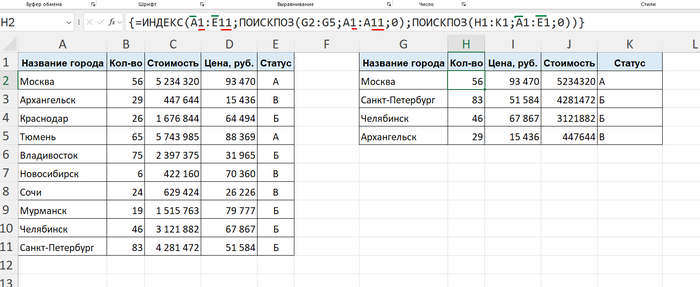
Формула написана только в ячейке Н2. Остальное - динамический массив.
И снова прилетает офисный нюанс: у вас в таблице не одна строка с Москвой, а несколько тысяч строк с разными городами. А ещё вы не зажиточный боярин, у которого версия Офиса 21+.
Проблема ПРОСМОТРX: динамический массив круто работает в одну строку. Но если вы попытаетесь кликнуть дважды по углу ячейки, чтобы протянуть формулу вниз на 5000 строк... Excel гордо ничего не сделает. Формулу динамического массива нельзя просто так взять и размножить вниз обычным автозаполнением (пока?). Придется либо тянуть мышку до мозолей вручную, либо городить костыли.
Ответ связки ИНДЕКС + ПОИСКПОЗ (INDEX + MATCH): и тут на помощь нам может прийти секретная техника — Формулы Массивов (привет всем, кто помнит и знает комбинацию клавиш Ctrl + Shift + Enter). Метод выглядит так: мы выделяем вообще весь пустой диапазон будущей таблицы, где должны быть значения, пишем одну формулу через ИНДЕКС и два ПОИСКПОЗ (один ищет строки, другой — столбцы), но только вместо одной ячейки указываем сразу все, которые нужно найти. Затем бахаем по клавиатуре тремя пальцами (но лучше спокойно сначала зажать Ctrl, потом Shift, а вот потом уже весело вдарить по Enter). И никакого закрепления ячеек! Сработает, кстати, даже если столбцы будут не по порядку.
Результат: огромная матрица данных заполняется за долю секунды. Без единой протяжки мыши. И, что самое приятное, этот трюк провернет даже древний Excel на компьютере вашей бухгалтерии, где про ПРОСМОТРX даже не слышали.
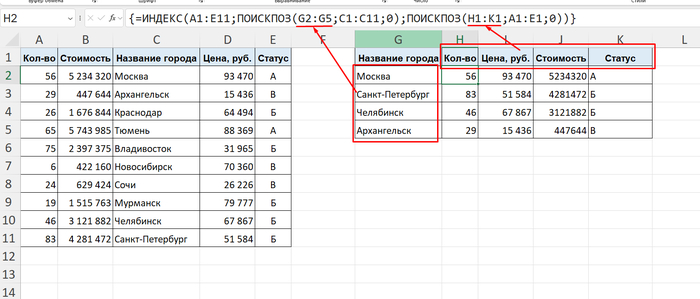
ВАЖНО! После того, как выделили диапазон, СРАЗУ нажимаем равно (=) и прописываем формулу. А ещё следите за тем, чтобы строки в ИНДЕКСЕ совпадали с первым ПОИСКПОЗ, а столбцы - со вторым.
Хочу донести главную мысль - не нужно усложнять формулы просто ради того, чтобы они выглядели "круто, современно и не как у всех". Каждый инструмент хорош на своем месте:
ПРОСМОТРX — идеален, если версия Офиса 21+, нужно по-быстрому связать пару табличек, подтянуть пару колонок.
ВПР + ПОИСКПОЗ — незаменим, когда колонок много, они перепутаны, так ещё и структура таблицы может меняться (но столбец с исходными значениями всегда слева).
ИНДЕКС + ПОИСКПОЗ — тяжелая артиллерия для двумерного поиска (и по строкам, и по столбцам одновременно) и работы с гигантскими массивами данных на любых версиях Excel. Плюс исходный столбец находится правее.
Так что не спешите забывать старые формулы — в умелых руках они экономят часы работы и кучу нервных клеток.
Всем спасибо за внимание. Надеюсь, кому-то был полезен данный материал. В комментариях делитесь своими необычными сочетаниями всем известных функций для решения нестандартных задач.
Для тех, кто хочет покрутить таблицы руками и повторить всё самостоятельно, вот ссылка на файл.




