

Безумные и странные эксперименты в homelab
5 постов
Вынос со скандалом Bcachefs из mainline-ядра Linux в конце 2025 года (начиная с релиза 6.18) проект не похоронил. Напротив, это явно подстегнуло мейнтейнера к жесткой дисциплине. Спустя 7 месяцев проект перешел на DKMS-модель и официально снял статус experimental.
Развернул тестовую ВМ в Proxmox, чтобы посмотреть на эксплуатационный UX: как ставится, как ведет себя при отказе дисков и стоит ли тащить в homelab или прод.
Дисклеймер. Это синтетические тесты, а не академический бенчмарк (на виртуалке поверх ZFS тестировать скорость - такое себе). Цель - проверить работу базовых функций, диагностику и поведение при аварии.
Тест проводился на Ubuntu 26.04 с ядром 7.0.0-22-generic. Штатного модуля в ядре дистрибутива нет, так что идем в официальный репозиторий за DKMS:
# Добавляем репозиторий apt.bcachefs.org (unstable / bcachefs-tools-release) и затем ставим всю обвязку
sudo apt install bcachefs-tools bcachefs-kernel-dkms fio btrfs-progs
По итогу получаем собранный модуль (bcachefs.ko.zst версии 1.38.6), и dmesg ожидаемо сыплющий ворнингами про tainting kernel и verification failed. Ну это просто надо иметь ввиду - теперь вы живете на внешнем модуле, и при каждом обновлении ядра нужно будет пристально следить за DKMS.
bcachefs: loading out-of-tree module taints kernel
bcachefs: module verification failed: signature and/or required key missing - tainting kernel
bcachefs: filldir64 fastpath disabled: struct layout unverified for this kernel
Первый тест был максимально тупой и прямолинейный:
Создать ФС на одном диске.
Смонтировать.
Записать файл 1 GiB и 5000 мелких файлов.
Запустить usage/scrub.
Размонтировать и выполнить offline check.
Для Bcachefs:
sudo bcachefs format -f -L bcf_single /dev/sdb
sudo mount -t bcachefs -o noatime /dev/sdb /mnt/bcf
sudo bcachefs fs usage -h -a /mnt/bcf
sudo bcachefs scrub /mnt/bcf
sudo bcachefs fsck -n -f /dev/sdb
Для Btrfs:
sudo mkfs.btrfs -f -L btr_single /dev/sdc
sudo mount -t btrfs -o noatime /dev/sdc /mnt/btr
sudo btrfs filesystem usage -T /mnt/btr
sudo btrfs scrub start -B /mnt/btr
sudo btrfs check --readonly /dev/sdc
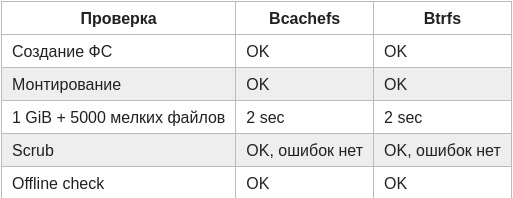
На этом этапе всё скучно, единственная практическая ценность тут - набор команд для создания ФС, может кому пригодится как шпаргалка.
Можно еще отдельно сказать про команды Bcachefs. Они непривычны, но в целом на удивление логичны: вместо mkfs.bcachefs используется bcachefs format, диагностика идёт через bcachefs fs usage, проверка через bcachefs fsck.
Для проверки сжатия использовал простой набор:
zero-512m.bin, 512 MiB нулей.
random-256m.bin, 256 MiB случайных данных.
Bcachefs создавалась сразу с zstd:
sudo bcachefs format -f -L bcf_zstd --compression=zstd /dev/sdb
Btrfs монтировалась с compress=zstd:
sudo mount -t btrfs -o noatime,compress=zstd /dev/sdc /mnt/btr
У Bcachefs понравилась отдельная секция в fs usage:

Итоговое использование места:
Bcachefs - около 283 MiB
Btrfs - около 274 MiB
Обе ФС отработали отлично (нули сжали, рандом пропустили). Разница в несколько мегабайт тут не имеет особого смысла.
Из интересного - у Bcachefs утилита fs usage выдает шикарную и очень наглядную статистику по сжатым/несжимаемым данным прямо в консоль.
Снапшоты проверял простым бытовым сценарием:
Создать subvolume.
Записать state.txt со значением original.
Создать read-only snapshot.
В живом subvolume поменять файл на changed.
Прочитать файл из snapshot.
Bcachefs:
bcachefs subvolume create /mnt/bcf/subv
bcachefs subvolume snapshot -r /mnt/bcf/subv /mnt/bcf/snap1
Btrfs:
btrfs subvolume create /mnt/btr/subv
btrfs subvolume snapshot -r /mnt/btr/subv /mnt/btr/snap1
Результат у обеих ФС одинаковый:
live=changed
snapshot=original
Здесь ноль сюрпризов. Снапшоты работают так, как от CoW-ФС и ожидаешь.
Теперь к цифрам. Ещё раз: это синтетические тесты внутри одного сомнительного стенда.
Параметры fio:
single disk
без сжатия
sequential read/write: bs=1M, size=2G
random write: bs=4k, numjobs=4, iodepth=16, runtime=30
Первые три строки ниже - это fio. Создание и удаление 10000 мелких файлов замерялись отдельно обычным shell-сценарием: создание дерева файлов и последующий rm -rf этого дерева.
Результаты:
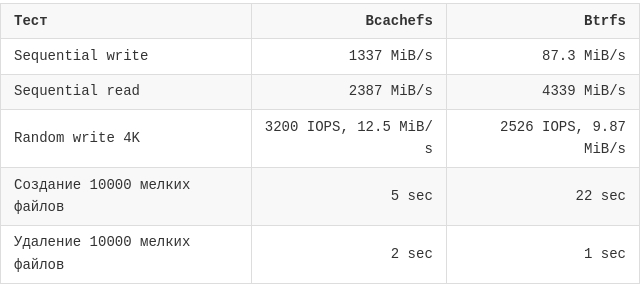
На этом стенде Bcachefs заметно быстрее на последовательной записи, random write 4K и создании мелких файлов. Btrfs, наоборот, быстрее на последовательном чтении и чуть быстрее удаляет дерево мелких файлов.
Само собой всё это автоматически не приводит нас к выводу, что Bcachefs быстрее Btrfs. Всё таки подложка в виде Proxmox/ZFS может сильно влиять на такие цифры. Но как лабораторный результат - как минимум любопытно.
Отдельный нюанс: во время нагрузки у Bcachefs в dmesg появилась строка:
bcachefs (sdb): bch2_journal_flush_seq stuck? Waited 10s for seq 32
После этого ФС нормально размонтировалась и прошла проверки. Но при эксплуатации это сообщение нельзя просто игнорировать. Его стоит отдельно разбирать при повторных тестах.
Одна из причин вообще смотреть на Bcachefs - обещание функциональности уровня современных CoW-ФС с более гибкой моделью устройств.
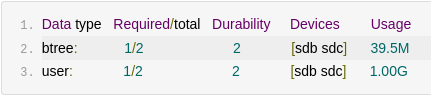
Bcachefs с двумя копиями данных и метаданных создаётся так:
bcachefs format -f -L bcf_raid1 --replicas=2 /dev/sdb /dev/sdc
После записи 512 MiB полезной нагрузки bcachefs fs usage показал ожидаемую репликацию:
Btrfs RAID1 создавался привычно:
mkfs.btrfs -f -d raid1 -m raid1 -L btr_raid1 /dev/sdb /dev/sdc
У него всё ожидаемо отображается через Data ratio: 2.00 и Metadata ratio: 2.00.
Нюанс в терминологии: у Bcachefs модель --replicas=2 читается проще. Мы описываем желаемое количество копий, а не выбираем отдельные RAID-профили для data и metadata. Для админа это вполне приятная деталь.
Ну и само собой важная часть для любой multi-device ФС нифига не красивая таблица fio, а поведение при отказе.
Сначала пробовал имитировать отказ изнутри гостевой ОС через /sys/block/*/device/delete и device/state=offline. В этой ВМ метод оказался ненадёжным: устройство либо оставалось видимым, либо состояние быстро возвращалось в running.
Поэтому финальный тест делал через QMP hot-unplug на уровне Proxmox/QEMU. Постоянную конфигурацию ВМ не менял, удалял только live-устройство.
Bcachefs
Сценарий:
Bcachefs на /dev/sdb и /dev/sdc.
Форматирование с --replicas=2.
Запись 256 MiB payload.
QMP device_del scsi2, то есть удаление второго диска.
Проверка чтения старого файла и запись нового файла.
После hot-unplug /dev/sdc исчез из lsblk. Чтение и запись продолжили работать:
/mnt/bcf/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/bcf/after-qmp-hotunplug.txt
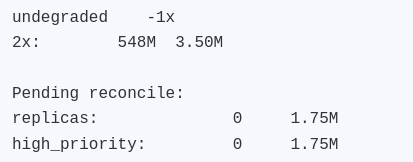
Диагностика Bcachefs показала, что часть метаданных уже требует восстановления реплик:
В dmesg появились ожидаемые ошибки по удалённому устройству:
bcachefs: error writing btree node ... sdc io: BLK_STS_OFFLINE
bcachefs (sdc): offline from block layer
bcachefs: error writing btree node ... sdc io: BLK_STS_REMOVED
Практический вывод: ФС осталась рабочей, данные читались, новая запись прошла. При этом состояние явно деградировало и требует дальнейшего reconcile/восстановления. Собственно, именно это и хотелось увидеть от теста.
Btrfs
Для Btrfs аналогичный сценарий делал на другой паре дисков:
Btrfs RAID1 на /dev/sdd и /dev/sde.
Так же запись 256 MiB payload.
QMP device_del scsi4.
Проверка чтения и запись нового файла.
После удаления /dev/sde ФС тоже продолжила работать:
/mnt/btr/payload.bin: OK
-rw-rw-r-- 1 user user 20 ... /mnt/btr/after-qmp-hotunplug.txt
btrfs filesystem usage -T показал missing device:
WARNING: failed to get device size for /dev/sde: No such file or directory
Device missing: 20.00GiB
В dmesg появились ошибки записи на удалённое устройство:
BTRFS error (device sdd): bdev /dev/sde errs: wr 1, rd 0, flush 0, corrupt 0, gen 0
BTRFS warning (device sdd): lost super block write due to IO error on /dev/sde (-5)
BTRFS error (device sdd): error writing primary super block to device 2
В этом конкретном сценарии обе ФС повели себя адекватно: RAID1-подобная конфигурация пережила потерю одного диска на живую, данные остались читаемыми, запись продолжилась.
Понравилось в Bcachefs:
bcachefs fs usage -h -a очень информативен.
Хорошо видно data/metadata, compression, btree и состояние устройств.
Модель --replicas=2 читается проще, чем отдельные профили -d raid1 -m raid1.
Снапшоты и subvolume-команды выглядят логично.
Потерю одного устройства при репликации ФС пережила.
Минусы:
Вместо нормальной поставки в составе ядра - поставляется как DKMS-модуль со всеми вытекающими (вообще надо было постараться настолько сильно выбесить мейнтейнеров ядра своим стилем разработки, чтоб тебя со скандалом вып*здили из mainline)
В dmesg был warning про bch2_journal_flush_seq stuck.
Сценарий возврата или замены диска после hot-unplug надо тестировать отдельно.
У Btrfs главный плюс скучный, но весомый: он давно есть в дистрибутивах, хорошо документирован, привычен и в принципе практически стабилен.
Bcachefs после снятия experimental уже имеет смысл тестировать в homelab.
В базовых сценариях ФС отработала нормально: создание, монтирование, scrub/fsck, сжатие, снапшоты, multi-device.
На этом стенде Bcachefs хорошо выступила на записи и мелких файлах, но это синтетические тесты.
Потерю одного диска при --replicas=2 Bcachefs пережила: данные читались, запись продолжалась, диагностика показала деградацию.
Если резюмировать, то основные вопросы пока не столько к самой ФС, сколько к эксплуатационной обвязке: DKMS, обновления ядра, загрузка модуля и восстановление после отказов.
ИМХО, для лаборатории, тестового NAS, домашнего стенда и удовлетворения инженерного любопытства - да, Bcachefs уже интересно гонять. Для продакшена или единственной копии важных данных - только после собственных аварийных тестов и с нормальными бэкапами.

В systemd 261 подвезли сразу несколько вещей, от которых у старой школы снова начнёт подёргиваться глаз и гореть пердак: systemd-sysinstall, IMDSD и storagectl.
Самое вкусное тут, конечно, systemd-sysinstall. Это попытка сделать нативный установщик ОС прямо внутри systemd. Не графический мастер с кнопкой "далее-далее-готово", а низкоуровневый механизм, который умеет ставить систему по описанию: разметка, образы, загрузчик, нужные системные компоненты. То есть ещё один кусок жизненного цикла Linux-системы переезжает под крыло systemd.
И это уже не просто "инициализация сервисов", в качестве которого systemd когда-то продали публике. За годы systemd стал отвечать за запуск, логи, сеть, DNS, домашние директории, шифрование, portable-сервисы, загрузку, контейнероподобные штуки, а теперь всё ближе подбирается к установке и управлению дисками.
IMDSD, Initramfs Management Daemon, выглядит как ещё один шаг в ту же сторону. Initramfs давно был местом, где у каждого дистрибутива свои скрипты, свои костыли, свои генераторы и вообще свой маленький уютный хаос. systemd предлагает сделать и этот слой более управляемым, предсказуемым и встроенным в общую модель.
storagectl туда же: управление хранилищами, блочными устройствами и всем, что лежит между железом и файловой системой. Не удивлюсь, если через пару лет обычный админ будет разбираться с дисками не через набор разрозненных утилит, а через очередную systemd-команду.
И вот тут начинается вечный холивар.
С одной стороны, systemd действительно решает реальную боль. Linux-инфраструктура исторически росла как набор отдельных инструментов, которые нужно склеивать руками, скриптами и молитвой. Для серверов, облаков, immutable-систем и автоматической установки единая модель управления выглядит логично. Особенно если хочется воспроизводимости: описал систему, получил систему.
С другой стороны, ощущение "systemd поглощает всё" никуда не делось. Просто потому что он и правда поглощает всё. Так уж получилось что недоделок в Linux-стеке всё же много, а systemd приходит туда с рабочим кодом, документацией и готовностью взять ответственность за ещё один неприятный слой.
Можно сколько угодно ворчать про монолитность и нарушение Unix-way, но реальность неприятнее: альтернативы часто либо фрагментированы, либо поддерживаются хуже, либо требуют от администратора слишком много ручной работы. systemd побеждает не потому, что всем нравится. Он побеждает потому, что закрывает скучные, но важные задачи.
Так что да, шутка про Systemd/Linux становится всё менее шуткой.
Сначала он запускал сервисы. Потом управлял логами, сетью, DNS и загрузкой. Теперь подбирается к установке ОС, initramfs и storage-слою.
Осталось дождаться systemd-kernel, systemd-bash и systemd-coffee.
Хотя ладно, последнее я бы, пожалуй, поставил.
Собрал коллекцию приёмов, которые превращают awk в отличную замену sort|uniq в задачах обработки текста.
uniq без sort - мой самый любимый трюк:
awk '!seen[$0]++'
Первое вхождение строки печатается, последующие - нет. А чтобы вывести только дубликаты:
awk '++seen[$0] == 2'
Подсчёт и суммы по группам:
awk '{g[$0]++} END {for (k in g) print g[k], k}' # count
awk '{g[$1] += $2} END {for (k in g) print g[k], k}' # sum
Пересечение двух файлов (ключ - NR==FNR работает только для первого файла):
awk 'NR==FNR {lut[$0]=1; next} $0 in lut {print}' FILE1 FILE2
Разность - заменить условие на !($0 in lut). Объединение - просто cat + uniq.
Важно: условие $0 in lut лучше, чем lut[$0], - последний при промахе создаёт пустые элементы массива и жрёт память на больших файлах.
Производительность:
- LC_ALL=C awk '...' - отключает Unicode, иногда даёт большой буст
- mawk вместо GNU awk - значительно быстрее
Контейнеры обеспечивают нам изоляцию, но по умолчанию они используют ядро хоста напрямую. А это значит, что общая поверхность атаки остается куда шире, чем многие думают. AppArmor (и его родственник SELinux, о котором мы поговорим как-нибудь позже) позволяет применять мандатный контроль доступа (MAC) на уровне приложений. Используя его связке с Podman или Docker, вы можете кардинально урезать возможности скомпрометированного процесса внутри контейнера по отношению к хост-системе.
В этом посте разберем процесс генерации рабочего профиля, его принудительного применения, отладки нарушений и чистой интеграции с вашей средой выполнения контейнеров - и всё это на базе типичной системы Debian/Ubuntu.
Казалось бы, ну ведь стандартные среды выполнения контейнеров уже дропают возможности (capabilities) и используют seccomp, нафига AppArmor? Но AppArmor добавляет к этому правила на основе путей и отслеживания возможностей, которые легко аудировать. Профиль может:
Запретить запись в чувствительные пути хоста, даже если внутри контейнера процесс запущен от root.
Ограничить разрешенные системные вызовы и операции с файлами сверх того, что предоставляет рантайм.
Выдавать вам понятные человеку логи, когда что-то пытается выбраться из своей «песочницы».
В Ubuntu AppArmor включен по умолчанию, а в Debian и Arch его активация - дело пары пустяков.
Для начала установим инструменты (пример для Debian/Ubuntu):
sudo apt update && sudo apt install apparmor apparmor-utils apparmor-profiles
Переведем целевое приложение в режим обучения (complain mode), чтобы понаблюдать за его реальным поведением:
sudo aa-genprof podman # или docker, или имя вашего бинарника
Утилита aa-genprof запускает программу в режиме обучения и следит за логами. Теперь запустите ваш контейнер в обычном рабочем режиме:
podman run --rm -it nginx:alpine sh
Погоняйте контейнер в хвост и в гриву (поустанавливайте пакеты, позаписывайте файлы и т.д.). Затем выйдете из него и позвольте утилите aa-logprof провести вас по процессу создания правил.
Минимальный готовый профиль (/etc/apparmor.d/podman-nginx) может выглядеть примерно так:
#include <tunables/global>
profile podman-nginx flags=(attach_disconnected,mediate_deleted) {
#include <abstractions/base>
#include <abstractions/nameservice>
capability net_bind_service,
capability setuid,
capability setgid,
network inet stream,
network inet6 stream,
/var/log/nginx/** rw,
/var/cache/nginx/** rw,
/etc/nginx/** r,
/usr/share/nginx/** r,
# Запрещаем доступ на запись к большей части /proc и /sys по умолчанию
deny /proc/** w,
deny /sys/** w,
# Разрешаем только конкретное чтение при необходимости
/proc/cpuinfo r,
/proc/meminfo r,
# Бинарник вашего приложения и библиотеки
/usr/sbin/nginx mr,
/usr/lib/nginx/** mr,
# Обработка сигналов
signal (receive) set=term,
# Запрещаем всё остальное по умолчанию
deny /** wl,
}
Инструмент aa-logprof шаг за шагом проведет вас по каждому залогированному событию и позволит выбрать: разрешить его, запретить или проигнорировать.
У Podman отличная интеграция с AppArmor. Запустите контейнер следующим образом:
podman run --security-opt apparmor=podman-nginx -p 8080:80 nginx:alpine
Убедитесь, что профиль действительно загружен:
sudo aa-status | grep podman-nginx
Вы должны увидеть его в режиме enforce (принудительное исполнение).
Для Docker (если вы всё еще его используете):
docker run --security-opt apparmor=podman-nginx nginx:alpine
Если что-то ломается, проверьте логи ядра:
sudo dmesg | grep apparmor
# или
sudo journalctl -xe | grep apparmor
Затем снова воспользуйтесь интерактивным профилировщиком:
sudo aa-logprof
Он покажет, какого именно правила не хватало. Типичный сценарий: нужно добавить конкретный путь вида /run/… или /tmp/…, который легитимно требуется вашему приложению.
В продакшене вы можете временно переключить профиль в режим обучения (complain):
sudo aa-complain /etc/apparmor.d/podman-nginx
После настройки верните всё обратно в режим принудительного исполнения:
sudo aa-enforce /etc/apparmor.d/podman-nginx
Запускайте каждый новый образ контейнера с автоматически сгенерированным профилем в режиме обучения (complain) на протяжении недели.
Храните профили в Git рядом с вашими манифестами развертывания.
Сочетайте это с флагом --cap-drop=ALL и строгим профилем seccomp для эшелонированной защиты.
Периодически используйте утилиту aa-unconfined, чтобы находить процессы, которые работают без ограничений.
Документация Ubuntu по AppArmor: https://ubuntu.com/server/docs/how-to/security/apparmor/
Страница AppArmor на Arch Wiki (отличные примеры): https://wiki.archlinux.org/title/AppArmor
Параметры безопасности Podman: man podman-run (ищите по ключевому слову apparmor)
Man-страницы для aa-genprof(8), aa-logprof(8) и apparmor(7)
Профили AppArmor относятся к той категории инструментов, которые настраиваются один раз и довольно долго не меняются (если конечно хорошо к этому подойти в первый раз). Первоначальные вложения времени в изучение aa-logprof окупятся в первый же раз, когда вы поймаете контейнер на попытке сделать то, чего он делать не должен.
Если вы уже гоняете Podman или Docker в продакшене без кастомных профилей AppArmor, то это одно из самых высокодоходных (с точки зрения ROI) улучшений безопасности, которые вы можете сделать на этой неделе. Начните с одного критически важного сервиса и двигайтесь дальше.
В Bash встроен синтаксис виртуальных путей вида /dev/tcp/host/port. Если попытаться открыть такой "файл" через редирект, Bash перехватит запрос и сам поднимет TCP-соединение.
Например:
exec 3<>/dev/tcp/example.com/80
printf 'GET / HTTP/1.1\r\nHost: example.com\r\nConnection: close\r\n\r\n' >&3
cat <&3
Это не замена нормальным HTTP-клиентам. Редиректы, HTTPS, заголовки, ошибки - всё это придётся обрабатывать руками.
Но как трюк для отладки, контейнера без curl или просто чтобы вспомнить, что Bash иногда умеет больше, чем кажется, выглядит красиво.
В мире Kubernetes принято считать, что requests и limits - это надежные границы, которые полностью изолируют приложения. По факту же, когда память на ноде заканчивается, абстракции кубера отходят на второй план, и в игру вступают механизмы ядра Linux.
Решил разобраться в деталях и провел серию тестов в песочнице (ALT Linux 11, Minikube на Proxmox). Ниже - что из этого получилось.
Важно сразу разделить три разных сценария:
memcg OOM - контейнер упёрся в собственный memory limit.
kubelet eviction - kubelet заметил давление по ресурсам на ноде и начал выселять pod’ы.
global OOM - памяти на ноде не хватило быстрее, чем kubelet успел что-либо сделать, и сработал kernel OOM Killer.
Если смешать эти три механизма, легко случайно сделать неправильные выводы.
Самый частый сценарий: приложение внутри контейнера выходит за свой limits.memory.
В Kubernetes memory limit контейнера в итоге превращается в ограничение на уровне cgroup. В cgroup v2 жёсткий лимит задаётся через memory.max. Если потребление памяти в этой cgroup доходит до лимита и ядро не может освободить достаточно памяти, возникает memcg OOM.
На ALT Linux 11 используется cgroup v2 - как и в большинстве современных дистрибутивов Linux по умолчанию. Для Kubernetes это важный нюанс: в типовой конфигурации kubelet на cgroup v2 для container cgroup выставляется memory.oom.group=1.
Проверить это можно прям на ноде:
cat /sys/fs/cgroup/.../memory.oom.group
Если там 1, то при OOM внутри конкретного контейнера ядро рассматривает процессы этого контейнера как единую группу и убивает их вместе. Это отличается от привычного поведения cgroup v1, где мог умереть один worker-процесс, а основной процесс контейнера продолжал жить, оставляя приложение в полуживом состоянии.
Но тут есть важная оговорка: для multi-container pod это не обязательно означает мгновенную смерть всех контейнеров pod’а.
Если OOM произошёл на уровне cgroup конкретного контейнера, будет убит именно этот контейнер. Если же давление по памяти возникло выше по иерархии cgroup или дошло до node/global OOM, поведение уже зависит от лимитов, QoS, oom_score_adj и того, кого ядро выберет жертвой.
Для диагностики полезно смотреть не только memory.max, но и memory.events:
cat /sys/fs/cgroup/.../memory.max cat /sys/fs/cgroup/.../memory.events
В memory.events можно увидеть счётчики вроде:
high max oom oom_kill oom_group_kill
Они помогают понять, что именно произошло: контейнер приблизился к лимиту, упёрся в memory.max, словил OOM или был убит группой.
В cgroup v2 есть не только memory.max, но и memory.high.
memory.max - это жёсткая граница. Если контейнер дошёл до неё и память нельзя освободить, будет OOM.
memory.high - это мягкий порог. При его превышении ядро начинает троттлить процессы в cgroup и заставляет их проходить через reclaim, то есть пытаться освобождать память до того, как ситуация дойдёт до убийства.
Звучит конечно красиво, но в Kubernetes есть нюанс: сам факт использования cgroup v2 ещё не означает, что memory.high реально настроен для ваших контейнеров.
Обычно memory limit контейнера мапится в memory.max. А вот активное использование memory.high связано с MemoryQoS и конкретной конфигурацией kubelet/runtime. Если MemoryQoS не включён или runtime не выставляет этот параметр, memory.high может оставаться равным max, то есть фактически не работать как предварительный тормоз перед OOM.
Проверять надо на живой ноде:
cat /sys/fs/cgroup/.../memory.high
Если там max, никакого троттлинга на этом уровне нет.
Когда память заканчивается на всей ноде, важную роль играет oom_score_adj. Это поправка, которую Kubernetes выставляет процессам контейнеров, чтобы повлиять на выбор жертвы kernel OOM Killer’ом.
QoS-классы в Kubernetes такие:
Guaranteed
Pod получает Guaranteed, только если для каждого контейнера заданы и CPU, и memory request/limit, и при этом:
cpu request == cpu limit memory request == memory limit
Если забыли задать CPU request/limit - это уже не Guaranteed.
Для обычных пользовательских pod’ов это стандартный способ получить сильную защиту от OOM Killer’а:
cat /proc/$PID/oom_score_adj -997
BestEffort
Если у pod’а нет ни requests, ни limits, он получает BestEffort.
Такие процессы получают:
cat /proc/$PID/oom_score_adj 1000
Это первый кандидат на вылет при node/global OOM.
Burstable
Всё остальное - Burstable.
Для Burstable pod’ов oom_score_adj считается по формуле:
oom_score_adj = 1000 - (1000 × memoryRequestBytes) / nodeMemoryCapacityBytes
Результат зажимается в диапазоне:
[2, 999]
То есть чем больше memory request относительно памяти ноды, тем ниже oom_score_adj и тем меньше вероятность быть выбранным OOM Killer’ом.
В моей лабе это хорошо видно:
# Guaranteed pod
cat /proc/$(pgrep stress-ng)/oom_score_adj
-997
# BestEffort pod
cat /proc/$(pgrep alpine)/oom_score_adj
1000
Отдельный нюанс: системные процессы могут быть защищены ещё сильнее. В моей песочнице, например, kubelet имел oom_score_adj=-999, а sshd - -1000.
То есть Guaranteed - это не имба для пода. Это сильная защита по сравнению с обычными workload-процессами, но не абсолютная гарантия жизни.
Тут легко ошибиться.
oom_score_adj важен для kernel OOM Killer’а, когда ядро уже само выбирает, кого убить.
А kubelet eviction работает иначе. Если kubelet успевает заметить memory pressure до global OOM, он выселяет pod’ы по своей логике. Там важны:
превышает ли pod свои requests;
PriorityClass;
насколько сильно usage превышает request.
QoS-класс коррелирует с этим поведением, но не является единственным алгоритмом eviction.
Например, pod с низким priority, но потреблением в пределах request, не обязательно будет выселен раньше pod’а с более высоким priority, который сильно вышел за request. Поэтому для анализа инцидента надо понимать, что именно произошло:
контейнер умер из-за своего memory limit;
pod был выселен kubelet’ом;
процесс был убит kernel OOM Killer’ом при global OOM.
Это разные события, и следы у них разные.
Если память на ноде закончилась резко, kubelet может не успеть сделать eviction. Тогда срабатывает обычный kernel OOM Killer.
Для проверки я запускал простой Python-скрипт, который агрессивно захватывал память:
import time
data = []
while True:
data.append(bytearray(100 * 1024 * 1024))
time.sleep(0.1)
В dmesg после этого можно увидеть что-то вроде:
Out of memory: Killed process 1841 (python3) total-vm:10GB, anon-rss:3.7GB, oom_score_adj:0
Здесь важно правильно читать поля.
total-vm - это виртуальное адресное пространство процесса.
anon-rss - реально резидентные анонимные страницы в RAM.
Разница между total-vm и anon-rss хорошо показывает, почему нельзя смотреть только на VIRT в top/ps и делать вывод, что процесс реально занял столько RAM. Но это ещё не вся история overcommit. Для анализа overcommit лучше смотреть глобальные счётчики:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Committed_AS показывает объём памяти, который ядро уже пообещало процессам.
CommitLimit показывает предел, после которого новые аллокации в strict mode должны начать отклоняться.
Ещё один важный момент при разборе OOM-логов: не путайте строки invoked oom-killer и Killed process.
Строка вида:
python3 invoked oom-killer
описывает процесс, который наткнулся на нехватку памяти.
А строка:
Out of memory: Killed process ...
описывает уже выбранную жертву.
Иногда это один и тот же процесс, иногда нет.
В Linux есть три режима overcommit:
0 — эвристика ядра
1 — always overcommit
2 — strict overcommit
В моей лабе на ALT Linux 11 после старта Minikube/kubelet значение vm.overcommit_memory переключалось в 1.
Проверяется так:
sysctl vm.overcommit_memory
Важно: это node-level sysctl, а не настройка конкретного pod’а или cgroup. Он влияет на поведение всей ноды.
Режим 1 разрешает агрессивный overcommit: процессы могут успешно получать виртуальную память «про запас», а реальные проблемы проявятся позже - когда память начнут фактически трогать и страницы станут резидентными.
Самая опасная ситуация - вручную переключить ноду в strict mode:
sysctl vm.overcommit_memory=2
В режиме 2 ядро начинает проверять, не превышают ли обещанные аллокации общий commit limit.
Упрощённая формула такая:
CommitLimit = SwapTotal + RAM × overcommit_ratio / 100
Более точная формула учитывает huge pages:
CommitLimit = SwapTotal + (RAM - HugeTLB) × overcommit_ratio / 100
В моей лабе было 4 ГБ RAM, swap выключен, overcommit_ratio=50. Поэтому CommitLimit оказался около 2 ГБ:
sysctl vm.overcommit_memory=2
cat /proc/meminfo | grep CommitLimit
CommitLimit: 2005936 kB
Если нода уже нагружена и Committed_AS выше нового CommitLimit, такое переключение может быстро превратить систему в кирпич: новые процессы, fork, SSH-сессии и служебные демоны могут начать получать отказ на выделение памяти.
Перед включением strict mode надо хотя бы проверить:
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Если Committed_AS уже выше будущего CommitLimit, включать strict mode нельзя без подготовки.
Более безопасный порядок такой:
sysctl vm.overcommit_ratio=80
sysctl vm.overcommit_memory=2
Но и это не рекомендация «делать в проде». Это настройка, которую надо тестировать под конкретный workload. Kubernetes-кластер с контейнерами, JVM, Python, Go-сервисами, базами данных и sidecar’ами может очень неприятно отреагировать на строгий overcommit.
Чтобы нода не доходила до global OOM, Kubernetes даёт несколько механизмов резервирования.
kube-reserved - ресурсы для kubelet, container runtime и компонентов Kubernetes.
system-reserved - ресурсы для системных демонов ОС.
evictionHard - аварийный порог, при котором kubelet начинает выселять pod’ы.
Например:
kubeReserved:
memory: "512Mi"
systemReserved:
memory: "512Mi"
evictionHard:
memory.available: "500Mi"
Эти параметры не делают pod’ы магически безопасными. Они уменьшают Node Allocatable и создают буфер, чтобы kubelet успел начать eviction до того, как ядро сорвётся в global OOM.
Но если memory spike слишком резкий, kubelet всё равно может не успеть. Тогда решение будет принимать уже kernel OOM Killer.
8. Что делать в целях диагностики
Проверить версию cgroup
stat -fc %T /sys/fs/cgroup
Для cgroup v2 будет:
cgroup2fs
Найти cgroup процесса
cat /proc/$PID/cgroup
Проверить лимиты контейнера
cat /sys/fs/cgroup/.../memory.max
cat /sys/fs/cgroup/.../memory.high
cat /sys/fs/cgroup/.../memory.oom.group
cat /sys/fs/cgroup/.../memory.events
Проверить приоритет для OOM Killer’а
cat /proc/$PID/oom_score
cat /proc/$PID/oom_score_adj
Проверить overcommit
sysctl vm.overcommit_memory
sysctl vm.overcommit_ratio
grep -E 'CommitLimit|Committed_AS' /proc/meminfo
Проверить события Kubernetes
kubectl describe pod <pod>
kubectl get events --sort-by=.lastTimestamp
Если контейнер умер из-за собственного лимита, обычно будет видно OOMKilled.
Если pod выселил kubelet, будет Evicted.
Если был global OOM на ноде, следы надо искать уже в dmesg/journal:
dmesg -T | grep -i -E 'out of memory|oom|killed process'
journalctl -k | grep -i -E 'out of memory|oom|killed process'
requests и limits - это важные механизмы, но они не отменяют реальность Linux memory management.
Ключевые выводы всего вышеописанного:
Memory limit контейнера - это cgroup-лимит, а не предварительно зарезервированная RAM.
На cgroup v2 при memory.oom.group=1 процессы внутри контейнера обычно убиваются как группа. Но для multi-container pod это не всегда означает смерть всех контейнеров pod’а.
memory.high - полезный механизм cgroup v2, но не надо считать, что Kubernetes всегда его использует. Проверяйте реальное значение в cgroup.
QoS влияет на oom_score_adj, но kubelet eviction и kernel OOM Killer - разные механизмы.
Guaranteed - это сильная защита, но не гарантия бессмертия для пода. Системные процессы могут быть защищены сильнее, а при тяжёлом global OOM ядро всё равно будет кого-то убивать.
Strict overcommit mode опасен без расчёта Committed_AS и CommitLimit. Особенно на Kubernetes-нодах, где много процессов активно резервируют виртуальную память.
kube-reserved, system-reserved и evictionHard нужны не для красоты. Они дают kubelet шанс выселить pod’ы раньше, чем нода попадёт в global OOM.

Впрочем ладно, я зря драматизирую. AUR всегда был изрядной помойкой. Так что новость не удивительна (удивителен скорее масштаб).
Для тех кто всё еще не в курсе (хотя у арчеводов подгорает уже почти неделю). История следующая:
Более 1500 пакетов в Arch User Repository оказались заражены малварью в результате скоординированной атаки на цепочку поставок.
Атака была обнаружена на прошлой неделе. Злоумышленники загрузили скомпрометированные PKGBUILD-файлы, которые при сборке пакетов выполняли вредоносный код. Arch-команда уже объявила, что инцидент взят под контроль. Но это не отменяет масштаба трагедии. Свыше 1500 пакетов - это определённо дофига.

